データを手に入れたとき、集計や分析、数理モデル構築などをする前に、前処理をしデータをキレイにする必要があります。前処理を適切に行わないと、間違った何かを出力することになります。では実際に前処理はどのようなことをするのか。今回は「データの前処理とは何か」というお話しをします。
【目次】
1. なぜ前処理が必要なのか?
2. 4種類のデータ
3. データ統合
4. 特徴量エンジニアリング
5. 特徴量エンジニアリング|欠測値処理
6. 特徴量エンジニアリング|外れ値処理
7. 特徴量エンジニアリング|エンコーディング
8. 特徴量エンジニアリング|変数変換
9. データ削減
10.不均衡なデータセットへの対応
【この連載の前回:データ分析講座(その253)時系列データの5種類の特徴量(説明変数)へのリンク】
1. なぜ前処理が必要なのか?
データを集計したり分析したり数理モデル構築したりするとき、なぜ前処理が必要なのでしょうか?手に入れたデータの多くは、使いにくいデータ形式の状態になっています。使いやすい状態になっていても、ノイズや欠損値を含んでおり、そのまま使うことができない状態にもなっています。主な前処理は、例えば以下の4つです。
- データ統合
- 特徴量エンジニアリング
- データ削減
- 不均衡なデータセットへの対応
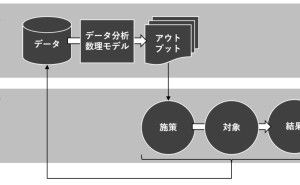
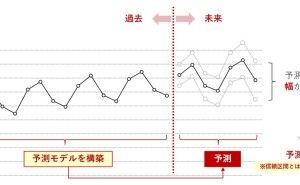
データの前処理を適切に実施することで、より良い情報をそのデータから抽出することができるようになります。言い方を変えると、前処理を適切に行わないと、間違った情報をデータから得ることもあります。数理モデル構築という観点でお話しすると、データの前処理を適切に実施することで、機械学習アルゴリズムを使い構築した予測モデルの精度を向上させます。要するに、予測モデルなどの数理モデル構築する上でも、データを集計し分析する上でも、前処理は非常に重要だということです。
前処理のお話しをする前に、データの種類について簡単に触れます。
2. 4種類のデータ
データの分類の仕方は色々あります。例えば、以下のような分類です。
- 数字データ
- テキストデータ
- 画像データ
- 音声データ
結局のところ、コンピュータで扱うには、テキストデータも画像データも音声データもデジタルな数字データへ表現し直されます。数字データは、例えば以下のようにさらに分類されます。
・量的データ(ニューメリカルデータ)
- 連続データ
- 離散データ(カウントデータ)
・質的データ(カテゴリカルデータ)
- 名目データ(非順序データ)
- 順序データ
3. データ統合
データ統合とは、複数のデータベースから必要なデータを抽出し、1つに統合することです。データ統合には、大きく以下の2つのアプローチがあります。
- 密結合(Tight Coupling)
- 疎結合(Loose Coupling)
疎結合アプローチの典型例は、ETL処理(Extraction, Transformation, and Loading processing)を実施し、元データの存在するデータベースとは別にデータベースなどを用意し、そこにETL処理後のデータを集約し統合する方法です。元データの存在するデータベースの内容が更新されても、ETL処理を実施しない限り、統合されたデータの存在するデータベースの内容が更新されることはありません。疎結合です。
密結合アプローチの典型例は、個々のデータベースに直接接続しクエリなどで抽出・統合する方法です。元データの存在するデータベースの内容が更新されると、統合されたデータは更新されます。密結合です。ちなみに、密結合はデータベース同士が密接に結びついている状態のことで、疎結合は緩やかに結合している状態です。
4. 特徴量エンジニアリング
特徴エンジニアリングは非常に重要です。欠測値処理や外れ値処理、変数変換などを実施していきます。場合によっては、変数の数が増大します。色々なものがありますし、色々な分類方法があります。例えば、以下の4種類です。
- 欠測値処理
- 外れ値処理
- エンコーディング
- 変数変換
それぞれについて、簡単によく使われる手法などを上げておきます。
5. 特徴量エンジニアリング|欠測値処理
データセットには欠損値はありがちです。欠測値をどのように扱うのかは、集計結果や分析結果、数理モデルに多大なる影響を与えます。しかし、慎重すぎると前に進めなくなります。そのため、大胆かつ慎重に取り扱う必要があります。よくある欠測値補完は以下の手法です。
- 統計量補完(平均値・最頻値・中央値などで補完)
- ランダム補完(分布を仮定し乱数を使って補完)
- 欠測値予測モデル補完(欠測値のないデータセットを使い予測モデルを構築し欠測値を予測し補完)
そもそも、欠測値の多い行や列は、欠測値保管しなんとかするのではなく、削除しましょう。
6. 特徴量エンジニアリング|外れ値処理
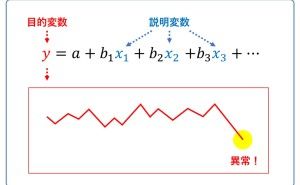
外れ値とは、他の値から異常な距離にある観測値のことです。外れ値を特定する前に、正常な値が何なのかを定義する必要があります。何を異常とみなすかは、データを分析する側に委ねています。そのための方法が幾つかあります。とく利用されているのは例えば、以下の2つです。
- 標準偏差の利用(例:平均値から標準偏差の3倍以上離れたデータを異常とみなす)
- IQR(四分位範囲Q3-Q1、箱ひげ図)の利用(例:Q1–3×IQより小さい、Q3 + 3×IQより大きい値のデータを外れ値とみなす)
予測モデルを利用(例:予測値と実測値の乖離が非常に大きい)
外れ値を検知した後に、意味のある外れ値なのか(現実に起こった無視すべきでないことなのか)、単なる記録ミス(システム上のエラーや、人的ミスなど)なのかで、その後の処理が異なります。状況によって、そのまま残したり、データそのものを削除したり、欠測値とみなして欠測補完することになります。そもそも、外れ値に強いアルゴリズムを使い数理モデルを構築する方法もあります。例えば、木系やSVM(サポートベクターマシン)系のアルゴリズムです。
7. 特徴量エンジニアリング|エンコーディング
質的データの変数などは、通常そのままでは扱えません。何かしらの量的データの変数で表現する必要があります。そのための方法がエンコーディングです。例えば、以下のような手法があります。
- ワンホットエンコーディング
- 平均値エンコーディング
- ラベルエンコーディング
- 順序エンコーディング
- 頻度エンコーディング
- 確率エンコーディング
この中で一番よく使われるのは、0-1変数で表現するワンホットエンコーディングです。
8. 特徴量エンジニアリング|変数変換
量的データの変数などを、変数変換し別の変数を作ることがあります。昔からよく、スケーリングを実施するための変数変換が、行われてきました。変数の単位を揃えるためです。例えば、以下のような変数変換です。
- 標準化(z-score normalization、Standardization)
- 正規化(min-max normalization)
- Box-Cox変換
標準化のとき、平均値の代わりに中央値や最頻値などを利用したり、標準偏差の代わりにIQR(四分位範囲)を用いたり、色々なバリエーションが考えられます。
9. データ削減
データ量の大きいデータセットを処理するためには、高い計算コストが必要になります。そこで、データ削減をすることが求められています。データ削減とは、元データの量を減らし、より小さなデータ量で表現する処理です。データ削減の技術で肝になるのは、データを削減しながらも、データの整合性を確保することです。主に2つのアプローチがあります。
- 次元削減
- 量削減
次元削減アプローチは、対象となるデータセットから変数を減らすことで、データ量を削減するものです。特徴量選択や主成分分析・因子分析などにより、高次元データを低次元データに変換することができます。
量削減アプローチは、単純に扱うデータ量や保存サイズを減らす方法です。例えば、ランダムサンプリングやクラスターサンプリングなどを実施し、元のデータの特徴を保持しつつデータ量を減らす方法があります。他にも、何かしらの数理モデルなどのパラメータのみを保存する、集約データのみを保存するなど、幾つか方法があります。
10. 不均衡なデータセットへの対応
正常・異常、離反・継続などの分類問題を扱う場合、クラス(例:正常や異常など)が極端に不均衡な状態になっている場合があります。極端に不均衡な状態になっている場合、このようなデータセットのクラスバランスを良くする必要がでてきます。クラスのバランスをとる方法が幾つかあります。例えば、データに重みを与えてバランスをとる伝統的な方法と、リサンプリング技術で対処する方法です。リサンプリング技術には、主に以下の3種類のものがあります。...