効果検証をする方法は色々あります。前回(第213話|データによる効果検証とネクストアクション)で上げたのが以下の3つです。
- AB比較分析
- Before&After分析
- 差分の差分析
Before&After分析とは、何か処置(例:プロモーション実施)されたときの前後を比較・分析することです。ありがちな分析かと思います。
例えば……
- 法定飲酒年齢の前後で死亡率がど変化するのか?
- キャンペーンの前後で売上がどう変化するのか?
……などです。
Before&After分析の1つに、回帰不連続デザイン(RDD)分析と呼ばれるものでがあります。今回は、「効果検証のための回帰不連続デザイン(RDD)分析」というお話しをします。
【目次】
1.回帰不連続デザイン(RDD)とは?
(1)アルコールの飲酒と死亡率の関係
(2)効果の大きさ≒境界線上の差(LATE)
2.回帰不連続デザイン(RDD)分析で登場する記号
3.パラメトリック回帰不連続デザイン(RDD)分析
4.ノンパラメトリック回帰不連続デザイン(RDD)分析
(1)営業・マーケティングの例
1.回帰不連続デザイン(RDD)とは?
回帰不連続デザインのRDDは、Regression Discontinuity Designの頭文字をとったものです。「回帰」というキーワードが入っていることから、回帰分析の親戚であることは想像が付くと思います。回帰不連続デザイン(RDD)とは、回帰分析を使い効果検証する手法の1つで、自然ルールではない人為的なルールによって生まれる境界線を利用した統計的因果推論の手法の1つです。統計学的因果推論は、当然ですが本当の因果ではありません。データから推論するだけです。その結果を使いどう解釈し実行に移すのかは人間に委ねられます。
(1)アルコールの飲酒と死亡率の関係
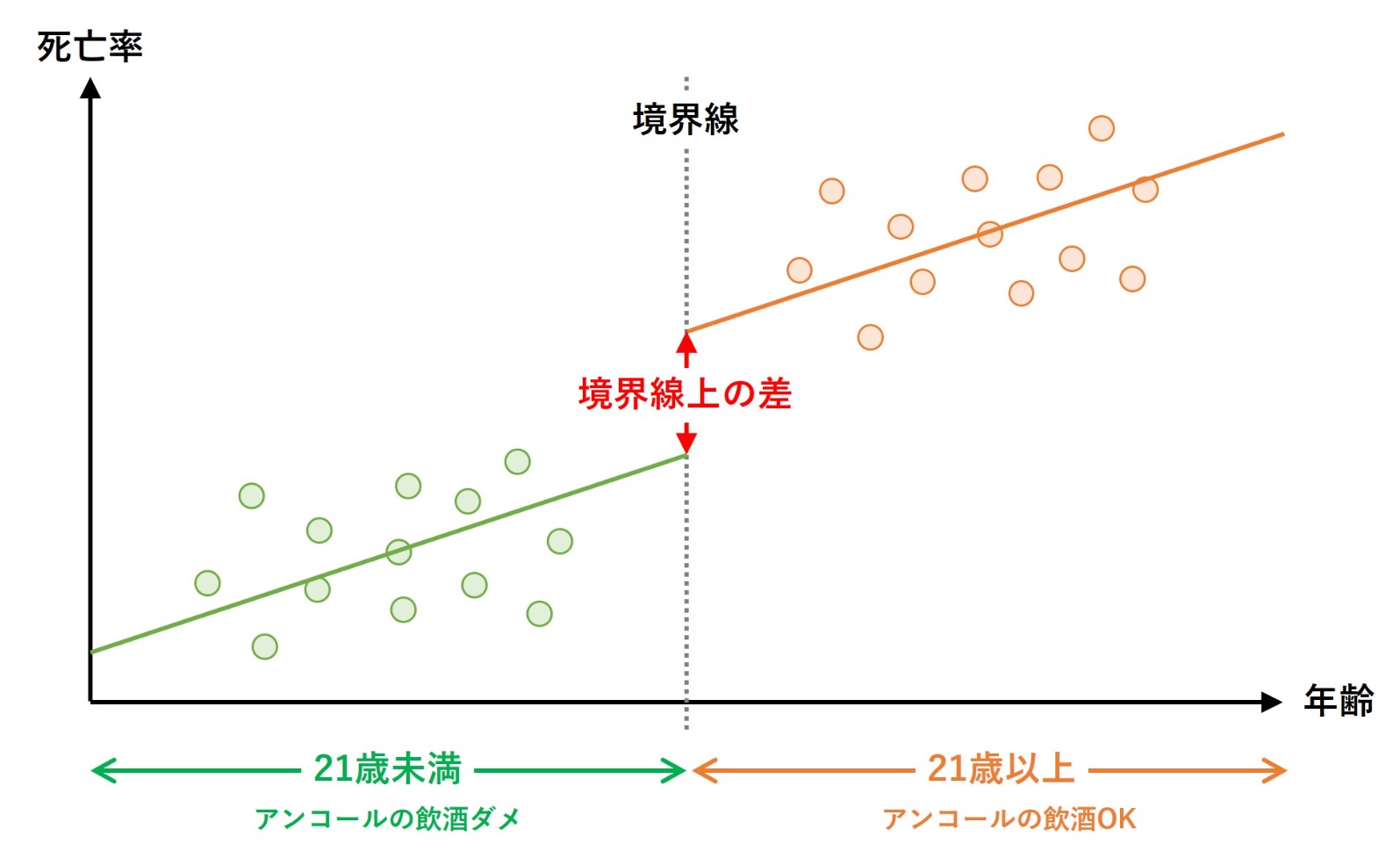
回帰不連続デザイン(RDD)の説明でよく登場する例で説明します。以下の参考文献にある、法定飲酒年齢が死亡者数に与える影響を分析した例です。
参考文献:Joshua D. Angrist, Jorn-steffen Pischke. 2008. Mostly Harmless Econometrics: An Empiricist’s Companion. Princeton: Princeton University Press. 日本語訳:「ほとんど無害」な計量経済学―応用経済学のための実証分析ガイド
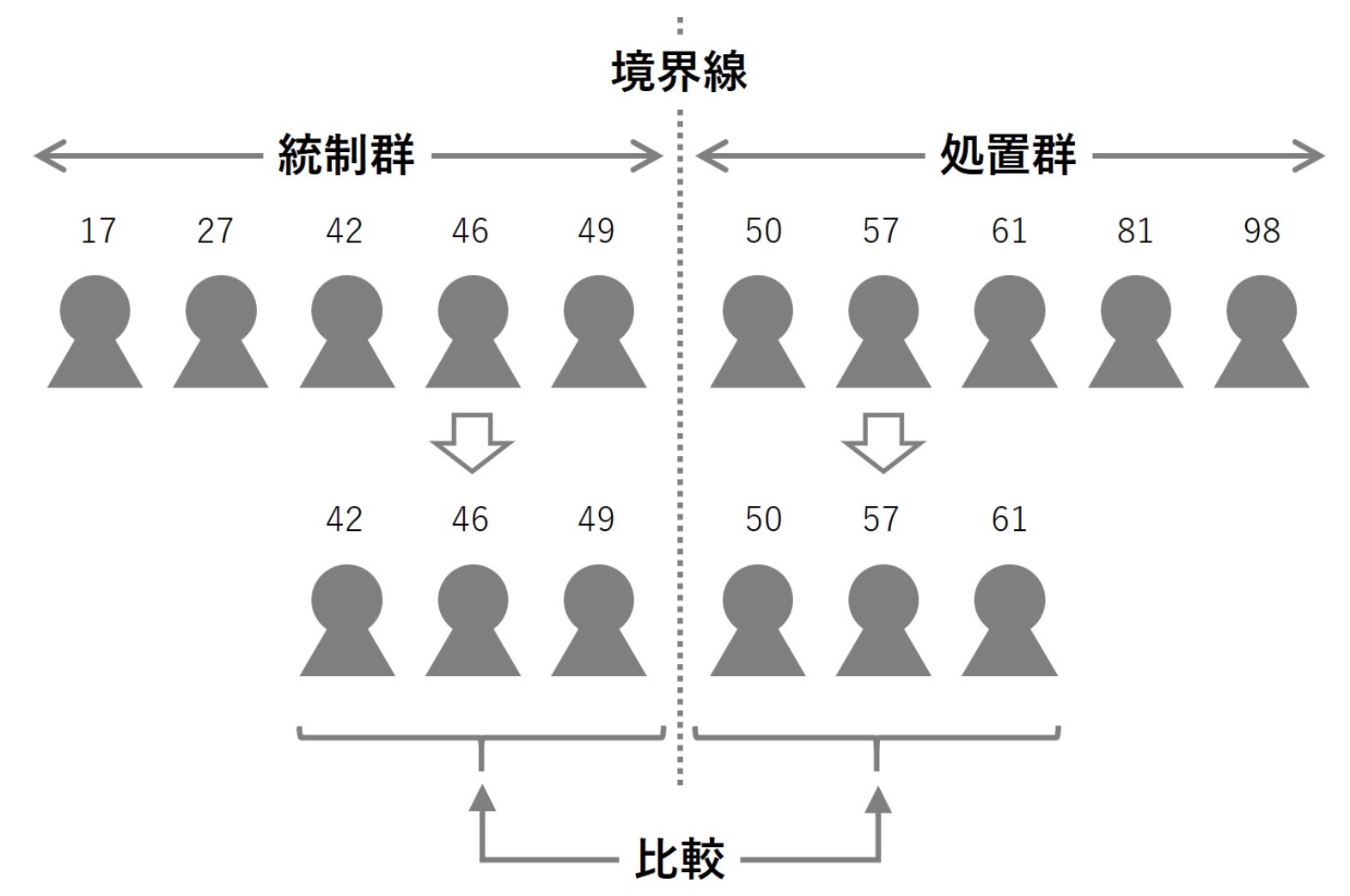
アルコールを飲酒していい年齢は、国によって異なります。米国では、法定飲酒年齢は21歳以上です。この場合、21歳が境界線(データのカットオフ)になります。
- 処置群:21歳以上(アンコールの飲酒OK)
- 統制群:21歳未満(アンコールの飲酒ダメ)
境界線付近の個体(人)は、ほぼ同じような人でしょう。そのため、処置群と統制群は境界線に近い場合のみ「ほぼ同じ」と仮定し、比較・分析をします。
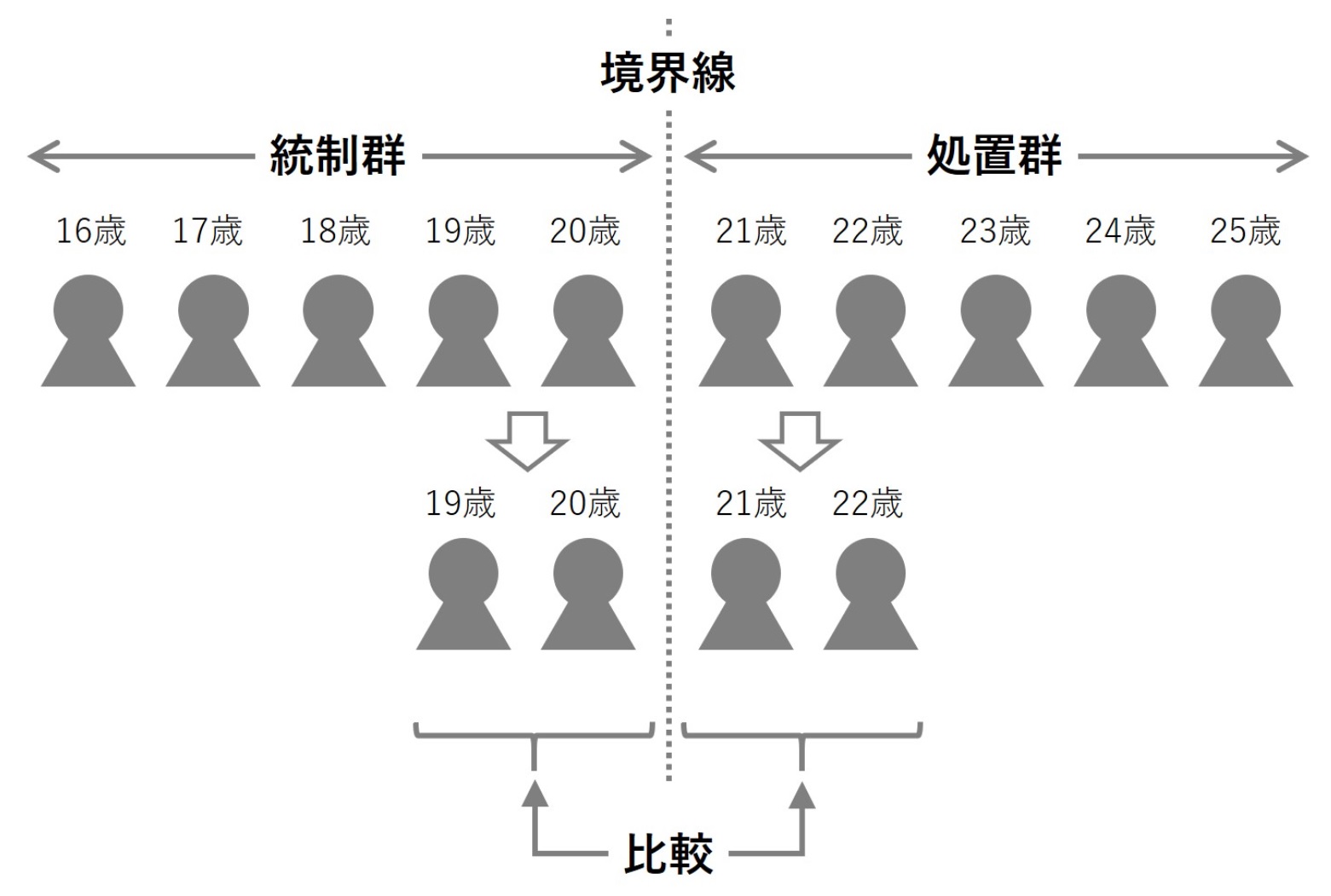
この境界線に近いところでは「ほぼ同じ」という仮定が満たされない場合には、回帰不連続デザイン(RDD)分析は有効ではありません。この仮定が満たされれば、21歳の誕生日(境界線)の前後で死亡率に違いがあれば、それは飲酒による影響に違いない、と考えます。このように何か人為的なルールを決めて実施したときの効果を知りたいときに利用できます。そういう意味では、マーケティングなどのキャンペーンやプロモーション施策などは、思いっきり人為的なものです。
(2)効果の大きさ≒境界線上の差(LATE)
端的に言うと、回帰不連続デザイン(RDD)で推定する「効果の大きさ」は「境界線上の差」です。
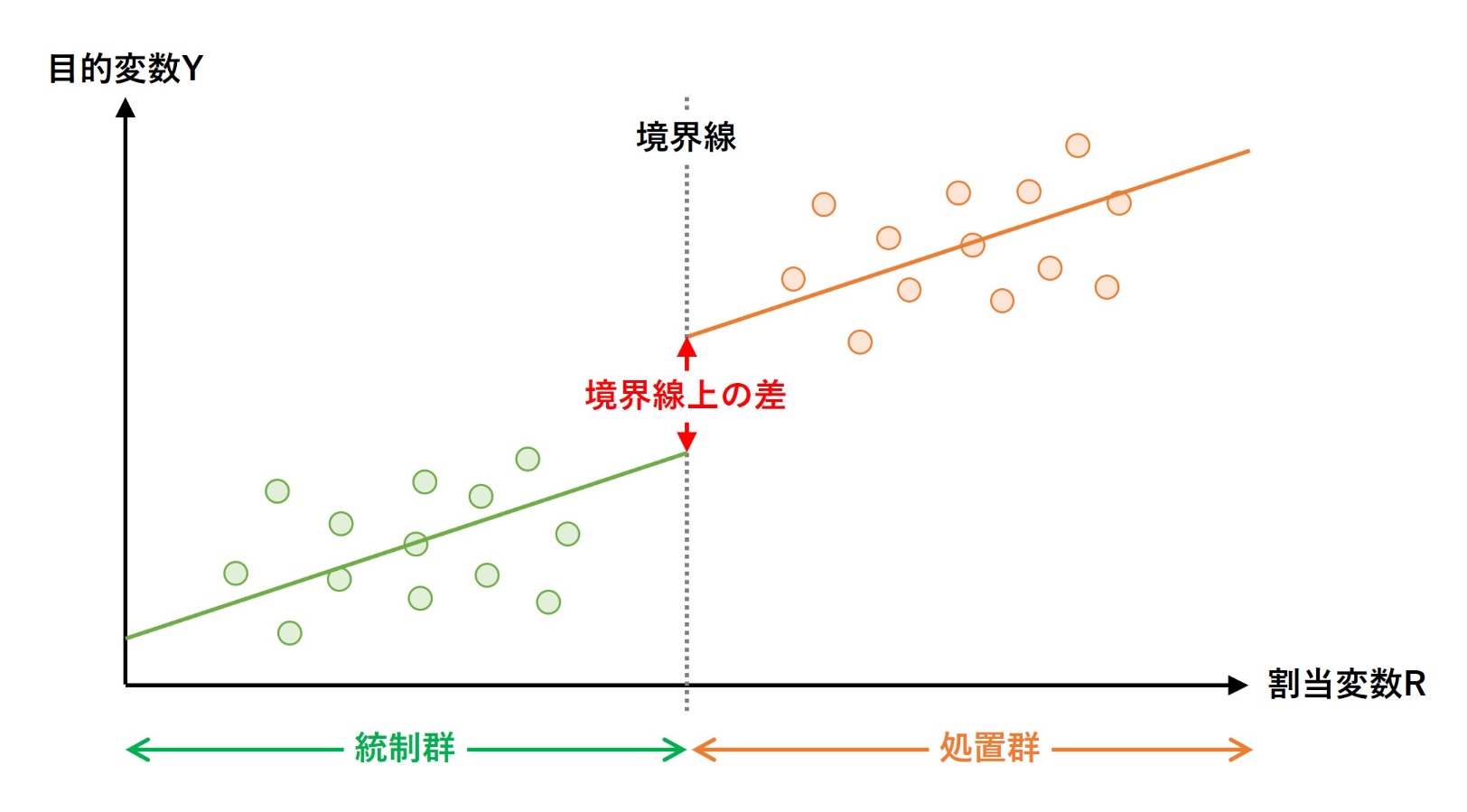
難しい用語で言うと「局所的平均処置効果」(local average treatment effect、LATE)、通常はLATEと言います。回帰不連続デザイン(RDD)分析で効果が分かるのは、境界付近のみでサンプル全体については分かりません。
2.回帰不連続デザイン(RDD)分析で登場する記号
回帰不連続デザイン(RDD)分析では、以下の3つの変数が登場します。
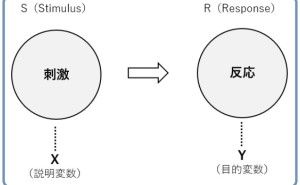
- 目的変数Y(例:死亡率)
- 処置変数D(例:21歳以上かどうかの0-1変数)
- 割当変数R(例:年齢)
ここで知りたいのは、処置変数Dが目的変数Yに与える影響です。これが、効果の大きさだからです。
このとき、割当変数Rは、目的変数Yと処置変数Dに影響を与えます。実際、処置変数Dは割当変数Rによって定義されます。
先ほどの例ですと……
- D=1 if R≧21
- D=0 if R<21
さらに、死亡率も年齢(R)によって変化することでしょう。では、実際にどうやって効果の大きさを推定するのでしょうか?
ざっくり2種類の回帰モデルを活用した方法があります。
- パラメトリック回帰モデル(重回帰など)
- ノンパラメトリック回帰モデル
3.パラメトリック回帰不連続デザイン(RDD)分析
通常の重回帰を使い、回帰不連続デザイン(RDD)分析するのが、最もシンプルでしょう。パラメトリック回帰不連続デザイン(RDD)分析と言います。
次のように定式化できます。 Y = α + ρD + βR + ε (ρが効果の大きさ)
先ほどの線形式は、最も単純なものです。通常は、多項式にしたり非線形にしたり他の変数を追加することもあります。以下は、先ほどお話しした「アルコールの飲酒と死亡率の関係」の「パラメトリック回帰不連続デザイン(RDD)分析」の結果です。
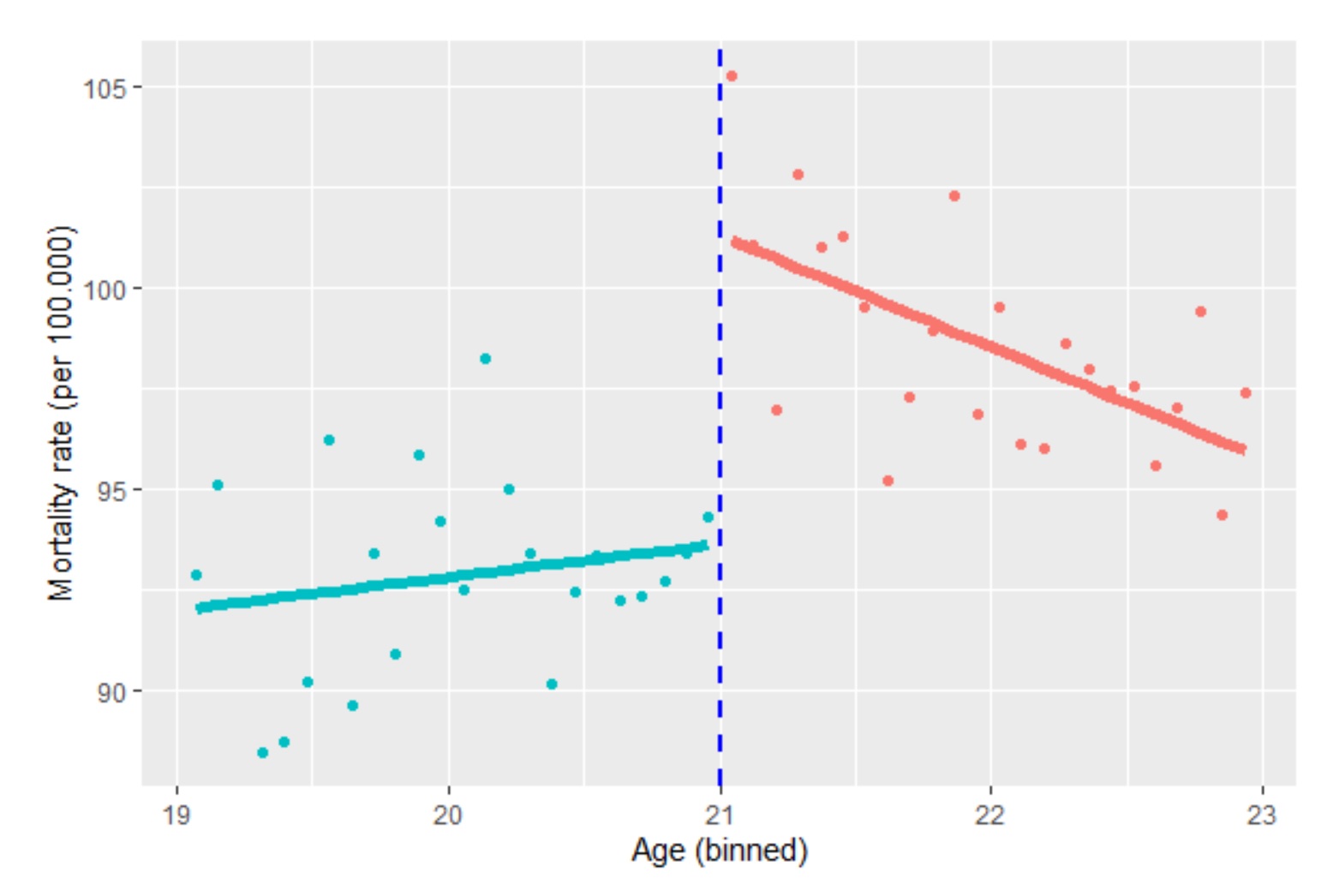
効果の大きさは7.66(標準誤差は1.32)です。
4.ノンパラメトリック回帰不連続デザイン(RDD)分析
重回帰のようなパラメトリックな回帰モデルではなく、ノンパラメトリックな回帰モデルを使い分析することもあります。ノンパラメトリック回帰不連続デザイン(RDD)分析と言います。パラメトリック回帰不連続デザイン(RDD)分析と違い、回帰式の関数の形が明確には分かりません。
また、パラメトリック回帰不連続デザイン(RDD)分析と違い、効果の推定で利用する幅(バンド幅、Bandwidth)を設定する必要があります。バンド幅は、幅を狭くするほどサンプルサイズが小さくなり精度が低くなります(標準誤差が大きくなります)が、バイアスも小さくなります。
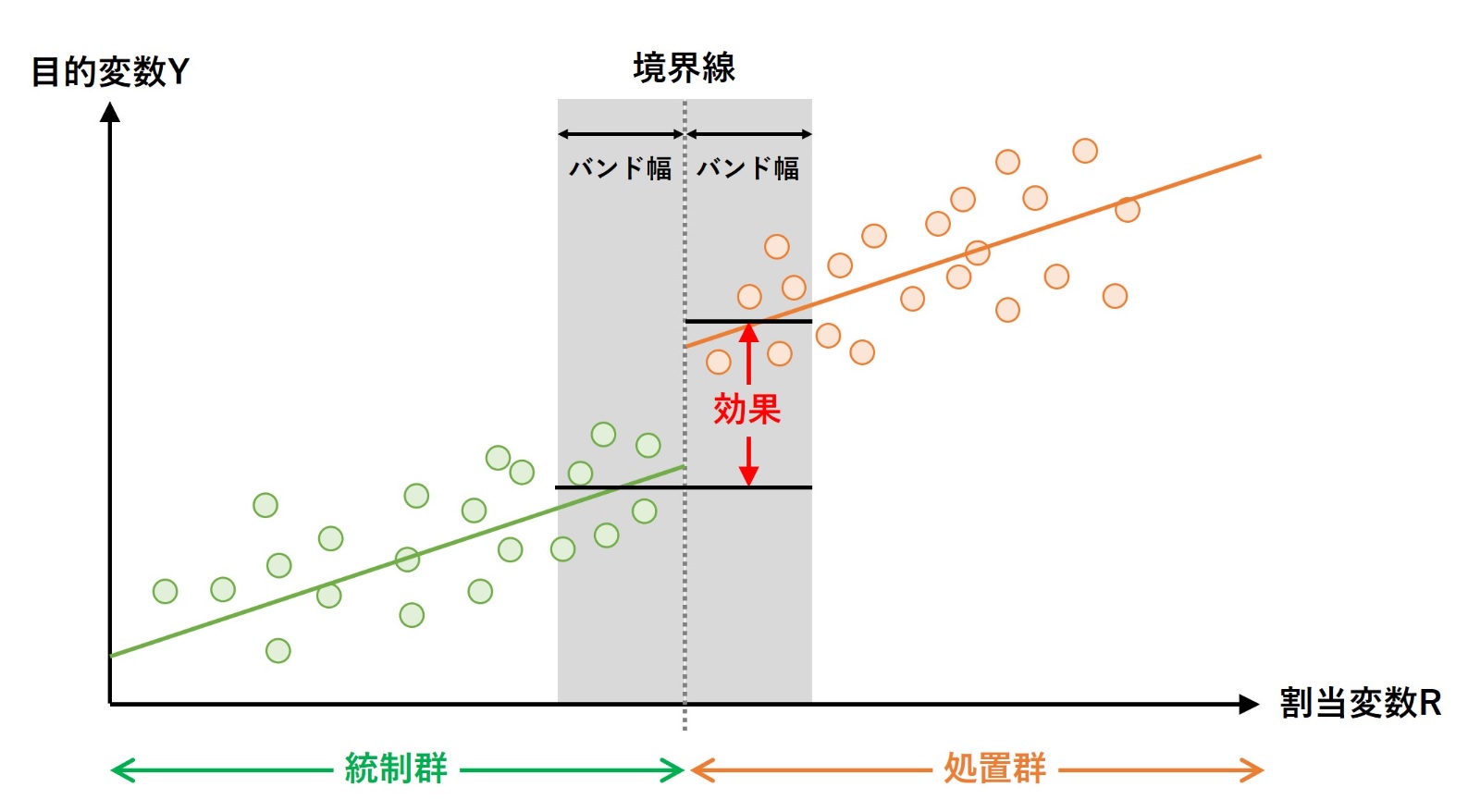
境界線の前後の「バンド幅内のYの推定値の平均値の差」がLATE(局所的平均処置効果、local average treatment effect)になります。以下は、先ほどお話しした「アルコールの飲酒と死亡率の関係」の「ノンパラメトリック回帰不連続デザイン(RDD)分析」の結果です。
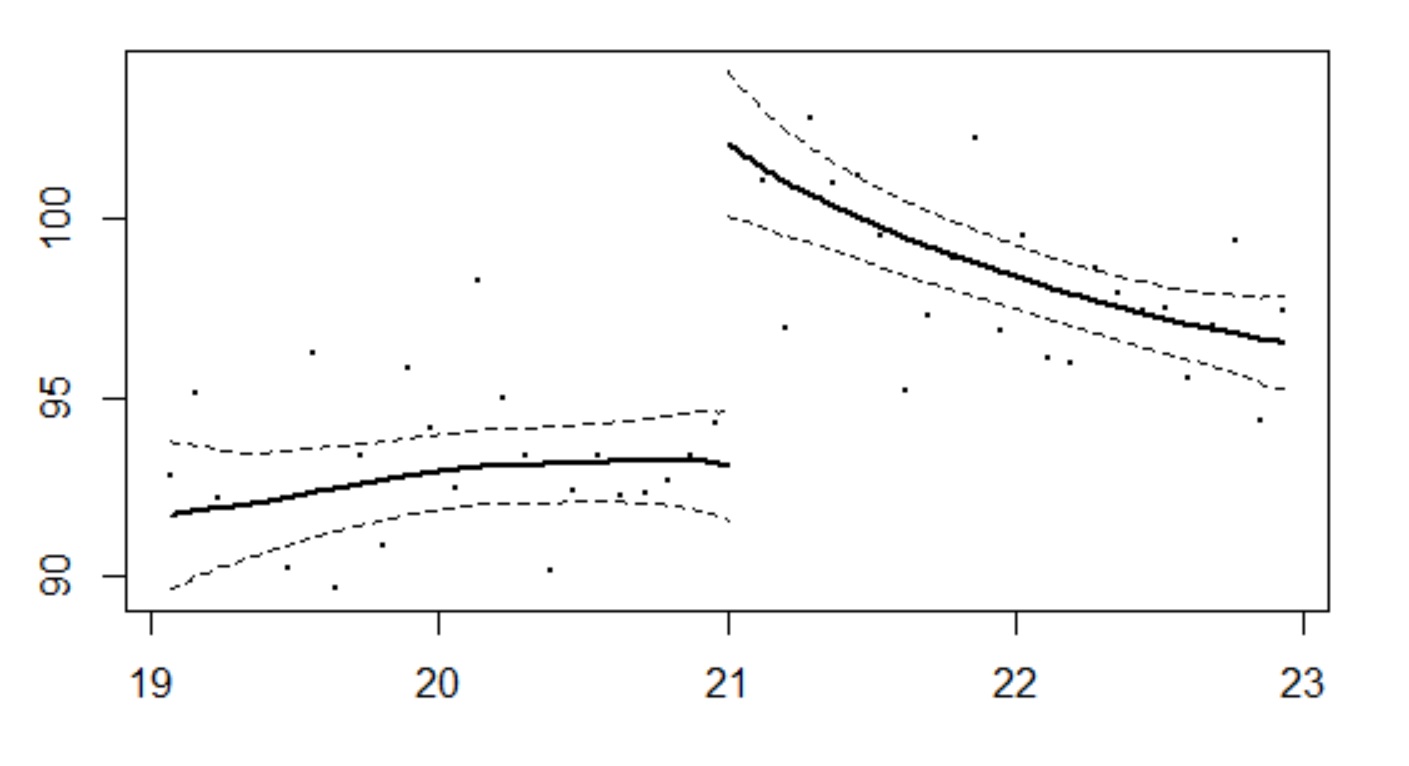
効果の大きさは9(標準誤差は1.48)です。...