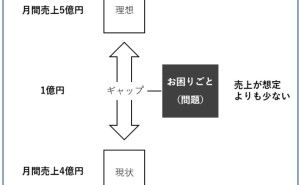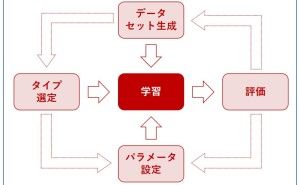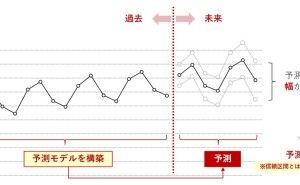

需要予測はビジネスの現場では非常に重要なことです。経験と勘による予測は、時間経過とともに上手く予測できなくなる危険性があります。なによりも再現性がありません。そのため、過去データをもとに需要予測モデルを構築し予測することは、需要予測業務を安定的に実施するという意味と、再現性の面から重要です。今回は「需要予測モデル構築時に検討すべき5つのポイント」というお話しをします。
【目次】
1. 5つのポイント
2. データ粒度(Granularity)
3. SKU集合(Sets)
4. 予測期間(Forecast horizon)を含む4つの時間
5. アルゴリズム(Algorithm)
6. 売上要因(Drivers)
【この連載の前回:データ分析講座(その250)顧客のチャーン予測(離反予測)へのリンク】
1. 5つのポイント
以下、需要予測モデル構築前に検討すべき5つのポイントです。
- データ粒度(Granularity)
- SKU集合(Sets)
- 予測期間(Forecast horizon)を含む4つの時間
- アルゴリズム(Algorithm)
- 売上要因(Drivers)
需要予測モデルを構築する前に、この5つのポイントを検討しておく必要があります。それぞれについて、説明していきます。
2. データ粒度(Granularity)
これは、売上×時間で検討していきます。
売上の粒度とは、全体・国別・事業別・エリア別・カテゴリー別・SKU(Stock keeping unit)別などのことです。時間の粒度とは、年単位・四半期単位・月単位・週単位・日単位・時間単位などのことです。
データサイエンス的には、粒度は細かい方が嬉しいです。しかし、現実はそう甘くはありません。そもそもデータが存在しないという可能性もありますし、データの粒度が細かいほどノイズの影響が大きくなり、外れ値処理などの処置が必要になります。
現実的には、ビジネス的な要求と、データ上の制約の間で決まることです。
3. SKU集合(Sets)
SKU (Stock keeping unit)の売上の時系列推移は、同じようなSKU(同じカテゴリーに属するSKUなど)ほど、似たような推移をします。
例えば、同じカテゴリーのSKUの需要予測を1つの予測モデルで実施するのか、SKUごとに個々に予測モデルを構築し実施するのか、という検討が必要になります。ここでモデリングの話しは避けますが、同じカテゴリーのSKUの需要予測を1つの予測モデルで実施する方が、データ量が増え、モデル構築という観点では好ましいのです。ただ、きめ細やかさが失われます。このあたりはバランスの問題です。
4. 予測期間(Forecast horizon)を含む4つの時間
予測期間(Forecast horizon)とは、予測開始時点(Cutoff)から予測する期間の長さです。
例えば、予測開始時点(Cutoff)は1日後、予測期間(Forecast horizon)は3ヶ月間とした場合、明日から3ヶ月間(CutoffからCutoff + Horizonの間の期間)を予測します。ちなみに、Cutoffは正確には、モデル構築時の学習データとテストデータを分けるポイントを指します。運用時は、取得できた過去データの次の日などを指します。さらに、学習データ期間(Rolling window size)、予測間隔(Period)の検討も合わせて必要になります。
要するに、次の4点を検討しておく必要があります。
- 予測間隔(Period):どのくらいの間隔(もしくは頻度)で
- 予測開始時点(Cutoff):どの時期を堺に
- 学習データ期間(Rolling window size):どのくらい過去のデータでモデルを学習し
- 予測期間(Forecast horizon):どのくらい先まで予測するのか
例えば……
- 予測間隔(Period):毎週月曜日の朝(もしくは日曜日の夜)に予測実施
- 予測開始時点(Cutoff):毎週月曜日
- 学習データ期間(Rolling window size):過去1年間のデータ
- 予測期間(Forecast horizon):1週間先(月曜日から日曜日まで)
……となります。
ここで、予測モデル検討時のCV(cross validation)のお話しをします。
需要予測モデルなどの時系列系の予測モデルを検証するとき、通常のCVは利用できません。なぜならば、時系列系の予測モデルの場合、時間の流れの中で過去のデータを使い未来を予測する、という前提があることと、その過去データは連続した時間のデータでなければならない、という前提があるからです。12月13日のデータを使って12月10日を予測することはない、ということです。
通常のCVのように、元のデータセットをランダムに分割すると、この前提が崩れてしまいます。時系列系の予測モデルの場合、この2つの前提を崩さずに、CVする必要があります。よく利用されるのがROCV(rolling-origin cross validation)というCVの方法です。
以下を元にデータセット幾つかに分解し、クロスバリデーションを実施していきます。
- 予測間隔(Period)
- 予測開始時点(Cutoff)
- 学習データ期間(Rolling window size)
- 予測期間(Forecast horizon)
実務でどのように活用するのか、という意味だけでなく、どのアルゴリズムが良いのか、というアルゴリズム選定上も、上記の4つの検討が必要になります。
5. アルゴリズム(Algorithm)
需要予測のための予測モデルを構築するアルゴリズムには、大きく2種類あります。
- 時系列データに対する時系列解析モデル
- テーブルデータ系の機械学習モデル
時系列データに対する時系列解析モデルとは、ARIMAモデルやProphetモデル、状態空間モデルなどが有名です。需要予測で利用する売上データなどが時系列データのため、非常に相性がいいのです。
テーブルデータ系の機械学習モデルとは、線形回帰モデルや決定木モデル、XGBoostなどのよく目にする機械学習モデルです。こちらは、一工夫必要です。特徴量(説明変数)を工夫して時系列風にして予測モデルを構築します。例えば、ラグ変数を追加する、周期成分を追加する、などです。テーブルデータ系の機械学習モデルの中では、決定木モデルやXGBoostなどの木系のアルゴリズムの予測精度が非常にいいです。
他にも、LSTM(Long Short Term Memory)のような時系列系のニューラルネットワークのアルゴリズムなどもあります。時系列系のニューラルネットワークのアルゴリズムも、色々なものがあります。テーブルデータ系の機械学習モデルと同様に、特徴量(説明変数)を工夫する必要があります。
以上のように、需要予測をするためのアルゴリズムには色々なものがあります。
需要予測をするための予測モデルを構築検討するとき、候補となる予測モデルをたくさん作ることになります。そのとき、どの予測モデルがいいのかを評価する必要があります。先程も述べましたが、よく利用されるのがROCV(rolling-origin cross validation)というCVの方法です。現実には、ROCVの結果の善し悪しだけでなく、計算スピードの問題や、解釈性の問題などを考慮し、どの予測モデルを利用するのかが決まるかと思います。
6. 売上要因(Drivers)
売上は通常、広告やキャンペーン、天候、曜日、などの影響を受けます。
これらの売上に影響を与える要因(Drivers)を把握しデータを入手し予測モデルに組み込むことができれば、需要予測の精度は向上します。先程あげたアルゴリズムは、売上要因(Drivers)がなくても予測モデルを構築することができます。過去の売上データのみだけで、予測モデルを構築することができるのです。
売上データのみで構築した予測モデルでも、データの粒度が荒い場合には、それなりの予測精度が出るケースが多いです。しかし、データの粒度が細かく...