
「実験室で最適だった反応条件が、工場の量産スケールでは再現できない」「日々の製造データが散在しており、新素材開発のプロセス最適化に活かせていない」データの力で開発期間を大幅に短縮する手法として『プロセスインフォマティクス(PI)』への関心が高まっていますが、導入には現場特有の障壁が存在します。本稿では、データの標準化、製造条件の複雑性、スモールデータ対策、組織の分断、そしてスケールアップのズレという5つの主要課題と解決策を解説します。この記事を読むことで、限られた実験回数で予測精度を高める能動学習の活用法や、ラボと実機のギャップを埋める差分学習の導入要領を習得できます。
<記事を最後までお読みいただくことで、実務における以下の課題や悩みが解決します>
- 過去の実験データが散在し、人工知能に学習させられない状態を解消する具体策がわかります。
- 複雑な製造条件の絡み合いを、経験や勘に頼らずに予測し最適化するアプローチが理解できます。
- 実験回数が限られる少量のデータ環境でも、効率的に予測精度を高めて成果を出す戦略が掴めます。
- 現場の研究者と情報技術人材の間の溝を埋め、組織として円滑にプロジェクトを推進するヒントが得られます。
- 研究室での成功を工場の量産ラインへスムーズに移行させ、スケールアップの「死の谷」を越える手法が学べます。
【会員様限定】 この先に、PIを「量産・事業化」へ繋げるための実務要諦があります
ここから先は、実験回数が限られる環境で精度を出す「スモールデータ対策」や、現場の研究者とIT人材の分断を解消する「リスキリング」の手法、そして実機へのスケールアップ時に生じるズレを補正する「差分学習(デルタラーニング)」について詳しく解説します。
この記事で得られる具体的ベネフィット
- 人工知能が次に必要な実験を逆算して提示し、無駄な試作を大幅に削減する「能動学習」の進め方がわかります
- ノーコードツールの活用により、ドメイン知識を持つ若手研究者を「データ活用人材」へ育成するステップが掴めます
- 実稼働データとシミュレーションを融合させ、トラブルを未然に防ぐ「デジタルツイン」の構築フローが理解できます
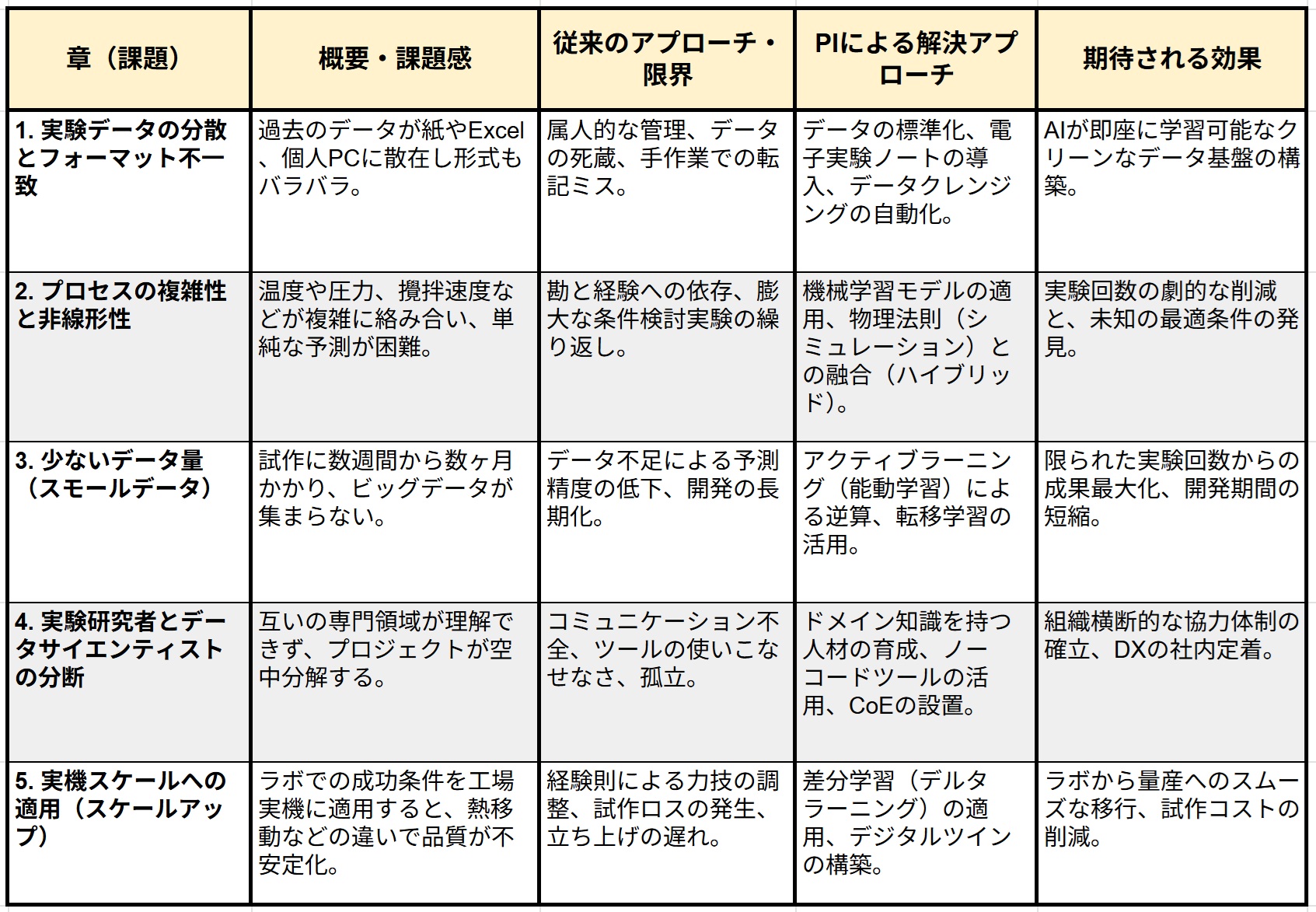
第1章:「実験データの分散とフォーマット不一致」という初期の壁
プロセスインフォマティクスを導入し、製造現場を革新しようと決意した企業が最初に行き当たるのが、過去データの取り扱いという現実的かつ非常に重たい課題です。長年にわたって蓄積されてきたはずの貴重な製造データや実験データは、実はすぐに活用できる状態にはありません。あるデータは色あせた紙のノートに手書きで記され、あるデータは担当者ごとの個人的な表計算ソフトに保存されています。また別のデータは、特定の測定機器から出力されたままの特殊なファイル形式で、個人のパソコンの中に眠っています。このようにデータが社内に散在し、形式も混在している状況は、機械学習を導入する際の重大な障害となります。人工知能は大量のデータを食べて成長しますが、その食べ物は適切に調理され、消化しやすい形に整えられている必要があるのです。
この壁を乗り越えるための最初のアプローチは、徹底したデータの標準化、すなわちデータの構造化です。まずは、社内に存在するデータの種類を洗い出し、どのような項目が必要かを定義するルール作りから始めます。温度や圧力、時間といった条件から、最終的な品質結果に至るまで、すべての単位や表記の揺れを統一します。例えば、ある人は温度を摂氏で記録し、別の人は華氏で記録しているかもしれません。また、ある人は材料の名前を略称で書き、別の人は正式名称で書いているかもしれません。こうした人間の目には明らかでも、コンピューターにとっては別物として認識されてしまう違いを一つ一つ潰していく作業がデータクレンジングです。
次に、これ以上「使えないデータ」を増やさないための仕組み作りが不可欠です。ここで有効なのが、電子化された実験ノートの導入です。これまで紙で行っていた記録作業をデジタルに置き換えることで、入力の段階からフォーマットが統一され、検索可能な構造化データとして保存されるようになります。プルダウンメニューでの選択や、測定機器からの自動データ取り込み機能などを活用することで、入力の手間を減らしつつ、入力ミスも防ぐことができます。
データの標準化とクレンジング、そして電子ノートを通じた新たなデータ収集基盤の構築。これらは非常に地道で時間のかかる作業であり、華やかな人工知能のイメージからは遠く離れているように感じるかもしれません。しかし、高品質なデータ基盤という強固な土台がなければ、いかに高度な機械学習の技術を用いても、得られる結果は信頼できないものになってしまいます。「ゴミを入れればゴミが出てくる」というデータ科学の格言があるように、データの品質こそがプロジェクトの成否を分ける最大の鍵なのです。この初期の壁から目を背けず、丁寧な土台作りを行うことが、プロジェクトを安定して進めるための重要な前提となります。
...
「実験室で最適だった反応条件が、工場の量産スケールでは再現できない」「日々の製造データが散在しており、新素材開発のプロセス最適化に活かせていない」データの力で開発期間を大幅に短縮する手法として『プロセスインフォマティクス(PI)』への関心が高まっていますが、導入には現場特有の障壁が存在します。本稿では、データの標準化、製造条件の複雑性、スモールデータ対策、組織の分断、そしてスケールアップのズレという5つの主要課題と解決策を解説します。この記事を読むことで、限られた実験回数で予測精度を高める能動学習の活用法や、ラボと実機のギャップを埋める差分学習の導入要領を習得できます。
<記事を最後までお読みいただくことで、実務における以下の課題や悩みが解決します>
- 過去の実験データが散在し、人工知能に学習させられない状態を解消する具体策がわかります。
- 複雑な製造条件の絡み合いを、経験や勘に頼らずに予測し最適化するアプローチが理解できます。
- 実験回数が限られる少量のデータ環境でも、効率的に予測精度を高めて成果を出す戦略が掴めます。
- 現場の研究者と情報技術人材の間の溝を埋め、組織として円滑にプロジェクトを推進するヒントが得られます。
- 研究室での成功を工場の量産ラインへスムーズに移行させ、スケールアップの「死の谷」を越える手法が学べます。
【会員様限定】 この先に、PIを「量産・事業化」へ繋げるための実務要諦があります
ここから先は、実験回数が限られる環境で精度を出す「スモールデータ対策」や、現場の研究者とIT人材の分断を解消する「リスキリング」の手法、そして実機へのスケールアップ時に生じるズレを補正する「差分学習(デルタラーニング)」について詳しく解説します。
この記事で得られる具体的ベネフィット
- 人工知能が次に必要な実験を逆算して提示し、無駄な試作を大幅に削減する「能動学習」の進め方がわかります
- ノーコードツールの活用により、ドメイン知識を持つ若手研究者を「データ活用人材」へ育成するステップが掴めます
- 実稼働データとシミュレーションを融合させ、トラブルを未然に防ぐ「デジタルツイン」の構築フローが理解できます
第1章:「実験データの分散とフォーマット不一致」という初期の壁
プロセスインフォマティクスを導入し、製造現場を革新しようと決意した企業が最初に行き当たるのが、過去データの取り扱いという現実的かつ非常に重たい課題です。長年にわたって蓄積されてきたはずの貴重な製造データや実験データは、実はすぐに活用できる状態にはありません。あるデータは色あせた紙のノートに手書きで記され、あるデータは担当者ごとの個人的な表計算ソフトに保存されています。また別のデータは、特定の測定機器から出力されたままの特殊なファイル形式で、個人のパソコンの中に眠っています。このようにデータが社内に散在し、形式も混在している状況は、機械学習を導入する際の重大な障害となります。人工知能は大量のデータを食べて成長しますが、その食べ物は適切に調理され、消化しやすい形に整えられている必要があるのです。
この壁を乗り越えるための最初のアプローチは、徹底したデータの標準化、すなわちデータの構造化です。まずは、社内に存在するデータの種類を洗い出し、どのような項目が必要かを定義するルール作りから始めます。温度や圧力、時間といった条件から、最終的な品質結果に至るまで、すべての単位や表記の揺れを統一します。例えば、ある人は温度を摂氏で記録し、別の人は華氏で記録しているかもしれません。また、ある人は材料の名前を略称で書き、別の人は正式名称で書いているかもしれません。こうした人間の目には明らかでも、コンピューターにとっては別物として認識されてしまう違いを一つ一つ潰していく作業がデータクレンジングです。
次に、これ以上「使えないデータ」を増やさないための仕組み作りが不可欠です。ここで有効なのが、電子化された実験ノートの導入です。これまで紙で行っていた記録作業をデジタルに置き換えることで、入力の段階からフォーマットが統一され、検索可能な構造化データとして保存されるようになります。プルダウンメニューでの選択や、測定機器からの自動データ取り込み機能などを活用することで、入力の手間を減らしつつ、入力ミスも防ぐことができます。
データの標準化とクレンジング、そして電子ノートを通じた新たなデータ収集基盤の構築。これらは非常に地道で時間のかかる作業であり、華やかな人工知能のイメージからは遠く離れているように感じるかもしれません。しかし、高品質なデータ基盤という強固な土台がなければ、いかに高度な機械学習の技術を用いても、得られる結果は信頼できないものになってしまいます。「ゴミを入れればゴミが出てくる」というデータ科学の格言があるように、データの品質こそがプロジェクトの成否を分ける最大の鍵なのです。この初期の壁から目を背けず、丁寧な土台作りを行うことが、プロジェクトを安定して進めるための重要な前提となります。
第2章:「プロセス(製造条件)の複雑性と非線形性」への対応
データ基盤が整い、いざ分析を始めようとしたときに立ち塞がるのが、製造プロセスそのものが持つ圧倒的な複雑さです。新しい材料を見つけるための情報学とは異なり、製造プロセスを最適化するプロセスインフォマティクスでは、単に「何を混ぜるか」という材料の組み合わせだけでなく、「どのように作るか」という工程の条件が結果を大きく左右します。温度の上げ方、圧力をかけるタイミング、混ぜ合わせる羽根の回転速度、そして装置の大きさなど、無数の変数が存在し、それらが互いに複雑に影響を与え合っています。
このような複雑な状況下では、ある条件を少し変えただけで、結果が急激に変化することが珍しくありません。温度を一定の割合で上げていけば、品質も一定の割合で良くなる、といった単純な正比例の関係が成り立つことは稀です。ある温度を超えた途端に急激に反応が進んだり、逆に全く反応しなくなったりするような、直感では予測が難しい非線形な挙動を示します。これまでの現場では、熟練の技術者が長年の経験と勘に基づいて、膨大な時間をかけて条件を少しずつ変えながら実験を繰り返し、最適な製造条件を手探りで探してきました。しかし、変数の数が増えれば増えるほど、人間が頭の中で考えられる組み合わせの限界を超えてしまいます。
この技術的課題を解決するためのアプローチが、機械学習モデルの適応と、物理法則を組み合わせたハイブリッド手法です。複雑な関係性を捉えるために、人間の直感では見出すことのできない隠れた規則性を見つけ出す高度な学習アルゴリズムを用います。これにより、多数の変数が同時に変化した際の結果を高精度に予測するモデルを構築します。
しかし、機械学習にも弱点があります。それは、過去のデータにない未知の領域の予測が苦手だということです。製造現場では、全く新しい条件での製造に挑戦しなければならない場面が多々あります。そこで力を発揮するのが、物理学や熱力学といった科学的な法則に基づいたコンピューターシミュレーションとの融合です。シミュレーションは、データがなくても「自然界のルール」に従って結果を計算することができます。
純粋なデータ駆動型の機械学習と、法則に基づいたシミュレーション。この二つを掛け合わせることで、データが不足している部分をシミュレーションが補い、シミュレーションでは計算しきれない複雑な現実の現象を機械学習が補正するという、互いの弱点を補完し合う強力なモデルが誕生します。このハイブリッドアプローチにより、経験や勘に頼った試行錯誤を排し、広範な条件の組み合わせの中から、的確に最適な製造プロセスを導き出すことが可能となります。
第3章:「少ないデータ量(スモールデータ)」でいかに精度を出すか
人工知能の発展を支えてきたのは、インターネット上に溢れる膨大な量のデータ、いわゆるビッグデータです。しかし、素材や化学品、医薬品などを生み出す製造業の現場において、ビッグデータは存在しないと言っても過言ではありません。工場で稼働している量産ラインのデータは蓄積されていても、新しいものを生み出すための研究開発の段階では、1回の試作を行うのに数週間から、長い場合には数ヶ月の時間を要することも珍しくありません。設備や人員、材料の制約がある中で、何千、何万回といった膨大な実験データを集めることは物理的にもコスト的にも不可能です。
このように、データが圧倒的に少ない「スモールデータ」の環境下で、いかにして精度の高い予測モデルを作り上げるか。これが、プロセスインフォマティクスを実践する上での最大の腕の見せ所となります。データが少ないからといって諦める必要はありません。少ないデータから最大限の情報を引き出し、効率的に正解へと近づくための戦略が存在します。
その中心となるのが、能動学習と呼ばれるアプローチです。一般的な機械学習が、人間が与えたデータを受け身で学習するのに対し、能動学習は「次にどのような実験を行えば、予測精度が最も効率的に向上するか」をモデル自身が計算し、人間に提案します。例えば、現在のモデルが「この温度と圧力の組み合わせの周辺は結果が全く予測できない」と判断した場合、まさにその未知の領域の実験を行うように指示を出します。人間が闇雲に実験条件を決めるのではなく、モデルの不確実性を最も効率的に減らすピンポイントの条件を逆算して提示するため、無駄な実験を極限まで省くことができます。
さらに、転移学習という手法も非常に有効です。これは、過去の別のプロジェクトや、似たような製造プロセスで学習した知識を、新しい全く別のプロジェクトに移植(転移)する技術です。人間が、自転車に乗れるようになればバイクの運転も比較的早く習得できるように、人工知能も過去の経験を活用することができます。これにより、新しい製品の開発をゼロからスタートするのではなく、すでにある程度「勘所の良い」状態から学習を始めることができ、ごくわずかな追加データだけでも高い精度の予測が可能になります。
スモールデータという制約は、決して乗り越えられない壁ではありません。能動学習による実験計画の最適化と、転移学習による過去の知識の再利用。これらのデータ効率化戦略を駆使することで、限られた時間と予算、そして少ない実験回数から最大の成果を生み出し、開発期間を大幅に短縮することができるのです。
第4章:「実験研究者とデータサイエンティストの分断」と社内リスキリング
技術的な壁を乗り越える手法が整ったとしても、プロジェクトが暗礁に乗り上げる原因となるのが組織的な壁です。プロセスインフォマティクスの導入において、多くの企業が頭を抱えるのが、「現場の実験研究者」と「情報技術の専門家であるデータサイエンティスト」の間の深い分断です。
現場で長年経験を積んできたベテラン研究者は、材料の性質や装置の微妙な癖、日々の温度や湿度の変化が結果に与える影響など、言葉にはしづらい暗黙の知識を豊富に持っています。しかし、統計学やプログラミングといったデータ科学の専門知識には明るくありません。一方で、データサイエンティストは高度な計算手法やプログラムの記述には長けていますが、現場のフラスコの中で実際に何が起きているのか、工場の配管の中で材料がどのように流れているのかといったリアルな現象を想像することができません。
この両者が顔を合わせても、使う言葉が全く違うためコミュニケーションが成立しません。データサイエンティストが「予測モデルの精度が十分に出ました」と提案した製造条件が、現場の研究者から見れば「そんな温度設定では材料が爆発してしまう、現場を知らない机上の空論だ」と一蹴されてしまうような悲劇が頻発します。結果として、互いに対する不信感が募り、プロジェクトは空中分解してしまいます。
この組織的課題を解決するには、双方の橋渡しとなる人材の育成と、共通の言語で会話できる体制の構築が不可欠です。最も理想的なのは、現場の専門知識(ドメイン知識)を持ちながら、データサイエンスの基礎も理解している「二刀流」の人材を育成することです。現場の若手研究者を対象にリスキリング(学び直し)の機会を提供し、データ分析の基礎を習得させることが有効です。彼らはデータサイエンティストのように複雑なプログラムをゼロから書く必要はありません。現在では、画面上の操作だけで直感的に機械学習を扱えるノーコードやローコードと呼ばれる便利なツールが普及しています。現場の研究者がこうしたツールを活用し、自らの手で日々のデータを分析できるようになれば、データサイエンティストとの会話は格段にスムーズになります。
さらに、組織全体の推進力を高めるためには、専門部署や推進チーム(センター・オブ・エクセレンス)を設置し、部門の垣根を越えた協力体制を作ることが重要です。このチームが中心となり、成功事例の共有や社内向けの実践的な研修を行うことで、データに基づく客観的な議論ができる文化を社内に根付かせていきます。技術と現場、二つの異なる世界をつなぐ共通言語と相互理解の仕組みを作り上げることこそが、プロジェクトを真の成功へと導く鍵となるのです。
第5章:「実機スケールへの適用(スケールアップ)」における予測のズレ
プロセスインフォマティクスを活用し、実験室の小さなフラスコやビーカーの中で、ついに画期的な最適な製造条件を発見したとします。しかし、ここで安心してはいけません。製品を世に送り出すための最大の難関が最後に待ち受けています。それが、実験室(ラボ)の規模から、工場の巨大なタンクを用いた大量生産ラインへと規模を拡大する際の「スケールアップ」と呼ばれる工程です。
ラボレベルで完璧にうまくいった条件を、そのまま工場の巨大な設備に当てはめても、決して同じ品質の製品は作れません。なぜなら、規模が大きくなることで、物質の混ざり方や熱の伝わり方が劇的に変化するからです。小さなコップの中で砂糖を溶かすのと、巨大なプールの中で砂糖を均一に溶かすのでは、必要な時間もエネルギーも全く異なるのと同じ理屈です。巨大なタンクでは、中心部分は熱くても外側は冷たいといった温度のムラが発生しやすくなります。このスケールアップに伴う予測不可能な品質の悪化や安定性の欠如は、多くの新製品開発を頓挫させてきたことから「死の谷」と恐れられています。
従来、この死の谷を越えるためには、少しずつタンクの規模を大きくしながら、途方もない回数の試作実験を繰り返し、現場の職人技で条件を微調整していくしかありませんでした。これには膨大な時間と、廃棄される試作品という莫大なコストがかかります。
このスケールアップの壁を越えるための強力なアプローチとして、近年注目を集めているのが差分学習(デルタラーニング)という手法です。これは、ラボでのデータで作られた予測モデルと、過去の工場での量産データとの間にある「ズレ(差分)」に着目する手法です。ラボでの理想的な状態から、実際の工場環境に移した際に、結果がどの程度、どのようにずれるのか。この「ズレの法則性」だけを集中的に人工知能に学習させるのです。これにより、ラボでの新しい実験結果から、いきなり工場での量産時の結果を高精度に予測することが可能になります。大規模な工場での試作を何度も繰り返すことなく、机上の計算でズレを補正できるため、試作コストと期間を劇的に削減できます。
さらに、この取り組みを究極の形へと進化させるのが、デジタルツインの構築です。デジタルツインとは、現実の工場の設備や配管、バルブの一つ一つに至るまでを、コンピューター上の仮想空間に全く同じ「双子」として再現する技術です。稼働中の実際の工場からリアルタイムで温度や圧力などのデータを収集し、仮想空間の双子に送り込みます。この仮想空間の中で、ハイブリッドモデルや差分学習を用いたシミュレーションを実行することで、現実の工場を動かす前に「この条件で製造をスタートしたら、三時間後の品質はどうなるか」を正確に予測できるようになります。
もし仮想空間内で品質の低下が予測された場合には、人工知能が自動的に最適な温度調整や攪拌速度の変更案を算出し、実際の工場の制御システムにフィードバックして未然にトラブルを防ぎます。ラボでの発見から、量産工場での安定稼働に至るまで。データと計算の力を駆使して、スケールアップに伴う不確実性を緩和すること。それが、プロセスインフォマティクスを実務に導入する主要なメリットであり、これからの製造プロセスを高度化させるための有効なアプローチとなります。


























