「自社の業務に特化したAIモデルを開発したいが、十分な学習データを集める時間も予算もない」と課題を感じていませんか? ゼロからAIを学習させるには膨大なデータと計算資源が必要ですが、実務の現場では用意できるリソースに限界があります。「自社特有の課題を解決したいが、学習データが不足している」「高性能な計算リソース(GPU)の確保が難しく、開発コストが膨らんでいる」、AIの実装を検討する際、こうしたリソースの制約が大きな障壁となっていませんか。今回は、学習済みモデルを再利用する「転移学習」の仕組みから、モデル選定の注意点、計算コストを抑える微調整の手法、そして精度維持のポイントを解説します。この記事を読むことで、限られたデータと予算内でAIプロジェクトを軌道に乗せるための具体的な判断基準と、開発プロセスを効率化する技術的要点を習得できます。
<記事を最後までお読みいただくことで、実務における以下の課題や悩みが解決します>
- 膨大な学習データや高額な計算機材が用意できず、AI開発が進まないという悩みの解消
- 既存のモデルを自社用に転用したものの、かえって精度が落ちてしまう「負の転移」の回避
- 巨大なAIモデルを、自社環境の限られたリソースで効率よく微調整する実践的なアプローチ
- AIが新しい知識を覚える際に、元の賢さを忘れてしまう「破滅的忘却」を防ぐ設定のコツ
- 少量のデータによる過学習を見抜き、実運用の中でAIを育てていく継続的なサイクルの構築
製造現場におけるAI学習方式の全体像と選定基準
製造業におけるDX(デジタルトランスフォーメーション)の進展に伴い、AIを活用した自動化や効率化が喫緊の課題となっている。しかし、現場の技術者が直面する最大の障壁は、AIモデルを構築するために不可欠な「学習データ」の量と質である。従来、深層学習(ディープラーニング)を用いて高い認識率を実現するためには、数万件から数百万件規模の膨大なラベル付きデータが必要とされてきた 。製造現場、特に高度に管理された生産ラインにおいては、不良品そのものの発生頻度が極めて低く、学習に必要な「不良品サンプル」を収集すること自体が困難であるという矛盾を抱えている 。このような背景から、現代の製造現場では、単一の学習方式に固執するのではなく、課題の性質や利用可能なリソースに応じて、機械学習、良品学習、不良品学習、そして転移学習といった多様なアプローチを戦略的に使い分けることが求められている 。特に「転移学習」は、すでに世の中に存在する「学習済みモデル」の知識を自社特有の課題に再利用することで、データ不足と計算コストの壁を同時に突破する有力な手段として注目されている 。以下の表は、製造現場で検討される主なAI学習方式の特性を、開発期間、データ量、認識率、および適応性の観点から比較したものである。
表. 製造現場における主要AI学習方式の比較表
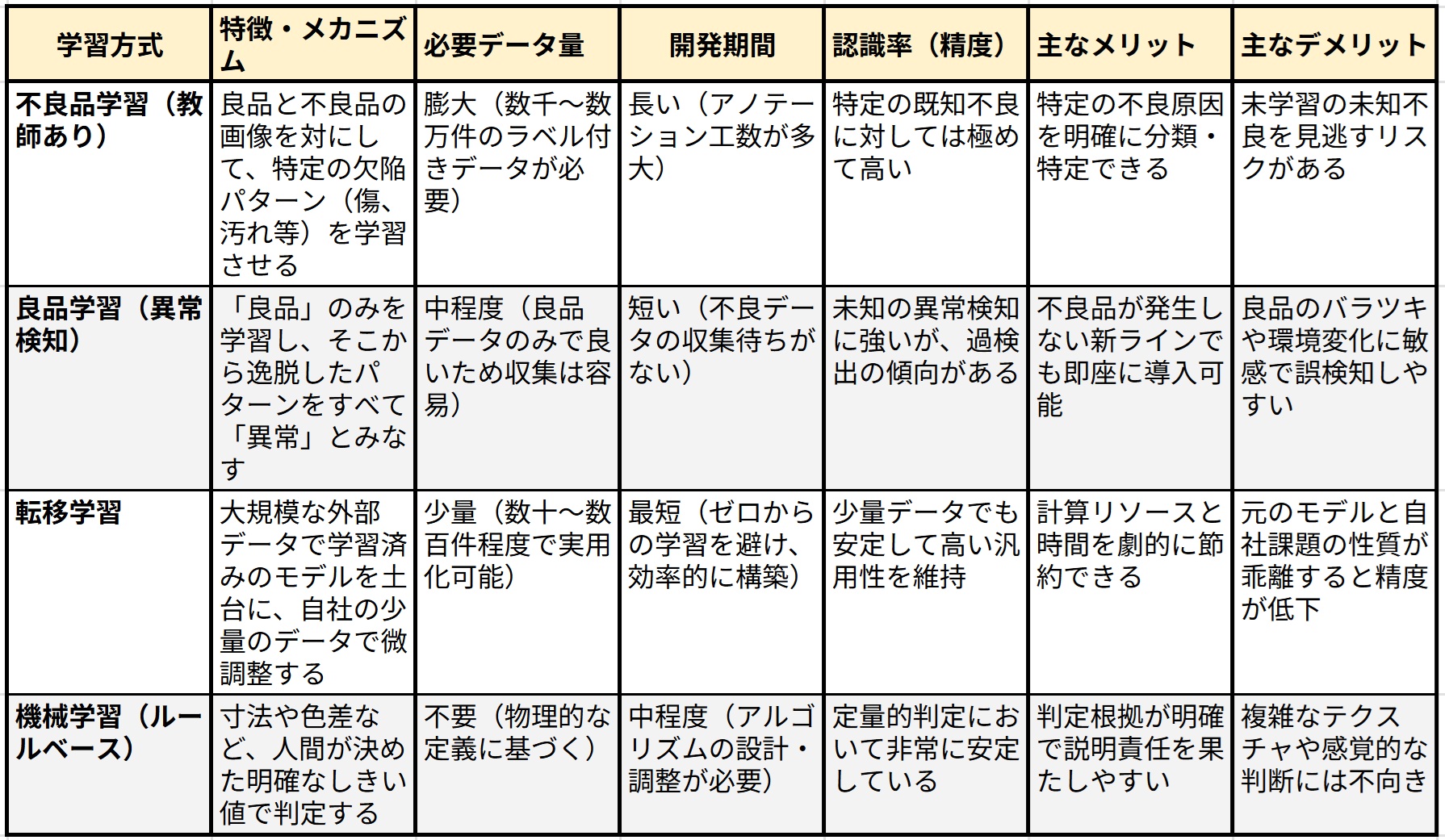
製造技術者にとって重要なのは、これらの方式が相互に排他的なものではないという視点である。例えば、新製品の立ち上げ直後は良品データのみを用いる「良品学習」からスタートし、運用過程で収集された不良データを「転移学習」を用いて既存モデルに組み込んでいくといった、段階的なアップデート(継続的学習サイクル)の構築こそが、現場に根ざしたAI運用の正解といえる 。
はじめに:AI開発の理想と厳しい現実
昨今、AI技術、特に深層学習(ディープラーニング)の進化は目覚ましく、画像認識や自然言語処理の分野では人間を凌駕する精度が報告されている。多くの企業がこの波に乗り、自社の製造ラインや保守点検業務にAIを組み込もうと画策している。しかし、いざプロジェクトを立ち上げると、現場の技術者はすぐに「理想と現実のギャップ」という高い壁に直面することになる 。その壁の正体こそが、「圧倒的なデータ不足」と「莫大な計算コスト」である。AIを賢く育てるためには、数万枚、時には数百万枚の高品質な学習データが必要とされるが、実務の現場では、そのようなリソースを用意することは不可能に近い 。特に「不良品を見つけるAI」を作りたい場合、不良品がめったに出ない高品質な生産ラインほど、学習に必要な「教師データ」が集まらないという皮肉な状況に陥る 。また、高性能なGPU(画像処理装置)を何台も並べて何日も計算を続けるような開発手法は、投資対効果(ROI)の観点から製造現場では許容されにくい 。このような「リソースを持たざる者」が直面する現代のAI開発のジレンマを打ち破るための実務的な武器が、「転移学習」という技術である 。本稿では、限られたデータと予算内でAIプロジェクトを軌道に乗せるための具体的な判断基準と、開発プロセスを効率化する技術的要点を、製造現場の視点から詳述する。
【会員様限定】 この先に、限られたリソースでAIを最適化する「実装の要諦」があります
ここから先は、巨大なモデルを安価な環境で微調整する「フリーズ」や「LoRA」といった具体的な手法、元の知識を忘れてしまう「破滅的忘却」の防ぎ方、そして実運用での精度維持について詳しく解説します。
この記事で得られる具体的ベネフィット
- 計算リソースを最小限に抑えつつ、モデルを最適化するパラメータ調整の手法がわかります
- 汎用性を保ちながら専門知識を追加する、繊細なチューニングのコツが掴めます
- 運用のなかでデータを蓄積し、AIを自律的に成長させる改善サイクルの構築法が理解できます
第1章:なぜ今「転移学習」なのか?データ不足とコストの壁を越える仕組み
AIに何かを学習させるという作業は、人間に例えるなら「新人教育」に似ている。何も知らない新入社員に、社会人の基礎マナーから自社の専門的な微細業務まで全てをゼロから教え込もうとすれば、膨大な時間と労力がかかる。これが、従来の「ゼロからのAI開発(スクラッチ学習)」が抱えていた最大の限界であった 。これに対し、転移学習とは、あらかじめ大量の一般的なデータを使って「基礎教育」を終えた優秀なAIモデル(基盤モデルや事前学習済みモデルと呼ばれる)を外部からスカウトしてきて、自社の業務に特化した「追加の教育」だけを施す手法である 。すでに世の中の形や色、物体間の境界といった「汎用的な知識の土台」を持っているため、自社で用意するターゲットデータはごく少量で済む 。
例えば、工場の製...
「自社の業務に特化したAIモデルを開発したいが、十分な学習データを集める時間も予算もない」と課題を感じていませんか? ゼロからAIを学習させるには膨大なデータと計算資源が必要ですが、実務の現場では用意できるリソースに限界があります。「自社特有の課題を解決したいが、学習データが不足している」「高性能な計算リソース(GPU)の確保が難しく、開発コストが膨らんでいる」、AIの実装を検討する際、こうしたリソースの制約が大きな障壁となっていませんか。今回は、学習済みモデルを再利用する「転移学習」の仕組みから、モデル選定の注意点、計算コストを抑える微調整の手法、そして精度維持のポイントを解説します。この記事を読むことで、限られたデータと予算内でAIプロジェクトを軌道に乗せるための具体的な判断基準と、開発プロセスを効率化する技術的要点を習得できます。
<記事を最後までお読みいただくことで、実務における以下の課題や悩みが解決します>
- 膨大な学習データや高額な計算機材が用意できず、AI開発が進まないという悩みの解消
- 既存のモデルを自社用に転用したものの、かえって精度が落ちてしまう「負の転移」の回避
- 巨大なAIモデルを、自社環境の限られたリソースで効率よく微調整する実践的なアプローチ
- AIが新しい知識を覚える際に、元の賢さを忘れてしまう「破滅的忘却」を防ぐ設定のコツ
- 少量のデータによる過学習を見抜き、実運用の中でAIを育てていく継続的なサイクルの構築
製造現場におけるAI学習方式の全体像と選定基準
製造業におけるDX(デジタルトランスフォーメーション)の進展に伴い、AIを活用した自動化や効率化が喫緊の課題となっている。しかし、現場の技術者が直面する最大の障壁は、AIモデルを構築するために不可欠な「学習データ」の量と質である。従来、深層学習(ディープラーニング)を用いて高い認識率を実現するためには、数万件から数百万件規模の膨大なラベル付きデータが必要とされてきた 。製造現場、特に高度に管理された生産ラインにおいては、不良品そのものの発生頻度が極めて低く、学習に必要な「不良品サンプル」を収集すること自体が困難であるという矛盾を抱えている 。このような背景から、現代の製造現場では、単一の学習方式に固執するのではなく、課題の性質や利用可能なリソースに応じて、機械学習、良品学習、不良品学習、そして転移学習といった多様なアプローチを戦略的に使い分けることが求められている 。特に「転移学習」は、すでに世の中に存在する「学習済みモデル」の知識を自社特有の課題に再利用することで、データ不足と計算コストの壁を同時に突破する有力な手段として注目されている 。以下の表は、製造現場で検討される主なAI学習方式の特性を、開発期間、データ量、認識率、および適応性の観点から比較したものである。
表. 製造現場における主要AI学習方式の比較表
製造技術者にとって重要なのは、これらの方式が相互に排他的なものではないという視点である。例えば、新製品の立ち上げ直後は良品データのみを用いる「良品学習」からスタートし、運用過程で収集された不良データを「転移学習」を用いて既存モデルに組み込んでいくといった、段階的なアップデート(継続的学習サイクル)の構築こそが、現場に根ざしたAI運用の正解といえる 。
はじめに:AI開発の理想と厳しい現実
昨今、AI技術、特に深層学習(ディープラーニング)の進化は目覚ましく、画像認識や自然言語処理の分野では人間を凌駕する精度が報告されている。多くの企業がこの波に乗り、自社の製造ラインや保守点検業務にAIを組み込もうと画策している。しかし、いざプロジェクトを立ち上げると、現場の技術者はすぐに「理想と現実のギャップ」という高い壁に直面することになる 。その壁の正体こそが、「圧倒的なデータ不足」と「莫大な計算コスト」である。AIを賢く育てるためには、数万枚、時には数百万枚の高品質な学習データが必要とされるが、実務の現場では、そのようなリソースを用意することは不可能に近い 。特に「不良品を見つけるAI」を作りたい場合、不良品がめったに出ない高品質な生産ラインほど、学習に必要な「教師データ」が集まらないという皮肉な状況に陥る 。また、高性能なGPU(画像処理装置)を何台も並べて何日も計算を続けるような開発手法は、投資対効果(ROI)の観点から製造現場では許容されにくい 。このような「リソースを持たざる者」が直面する現代のAI開発のジレンマを打ち破るための実務的な武器が、「転移学習」という技術である 。本稿では、限られたデータと予算内でAIプロジェクトを軌道に乗せるための具体的な判断基準と、開発プロセスを効率化する技術的要点を、製造現場の視点から詳述する。
【会員様限定】 この先に、限られたリソースでAIを最適化する「実装の要諦」があります
ここから先は、巨大なモデルを安価な環境で微調整する「フリーズ」や「LoRA」といった具体的な手法、元の知識を忘れてしまう「破滅的忘却」の防ぎ方、そして実運用での精度維持について詳しく解説します。
この記事で得られる具体的ベネフィット
- 計算リソースを最小限に抑えつつ、モデルを最適化するパラメータ調整の手法がわかります
- 汎用性を保ちながら専門知識を追加する、繊細なチューニングのコツが掴めます
- 運用のなかでデータを蓄積し、AIを自律的に成長させる改善サイクルの構築法が理解できます
第1章:なぜ今「転移学習」なのか?データ不足とコストの壁を越える仕組み
AIに何かを学習させるという作業は、人間に例えるなら「新人教育」に似ている。何も知らない新入社員に、社会人の基礎マナーから自社の専門的な微細業務まで全てをゼロから教え込もうとすれば、膨大な時間と労力がかかる。これが、従来の「ゼロからのAI開発(スクラッチ学習)」が抱えていた最大の限界であった 。これに対し、転移学習とは、あらかじめ大量の一般的なデータを使って「基礎教育」を終えた優秀なAIモデル(基盤モデルや事前学習済みモデルと呼ばれる)を外部からスカウトしてきて、自社の業務に特化した「追加の教育」だけを施す手法である 。すでに世の中の形や色、物体間の境界といった「汎用的な知識の土台」を持っているため、自社で用意するターゲットデータはごく少量で済む 。
例えば、工場の製造ラインで不良品を検知するAIを作りたいとする。不良品の画像は発生頻度が低いため、データが圧倒的に足りない。しかし、インターネット上にある数百万枚の一般的な写真であらかじめ学習を済ませた画像認識モデルを土台にすれば、そのモデルはすでに「物体の輪郭を見分ける力」や「模様の違いを認識する力」を十分に獲得している 。そこに数十枚から数百枚程度の自社の不良品画像を読み込ませるだけで、「なるほど、この製品特有の小さなキズを見つければいいのですね」と瞬時に理解し、実用レベルの精度を叩き出すことが可能になる 。
以下の表は、スクラッチ学習と転移学習の具体的な違いをまとめたものである。
表1:ゼロからの学習と転移学習の比較表

転移学習を採用することで、数千万円単位でかかっていた計算コストや開発期間を劇的に圧縮できるだけでなく、データの収集が困難なニッチなタスクにおいても高いパフォーマンスを追求できる 。
第2章:かえって精度が下がる罠。「負の転移」を防ぐ適切なモデル選定術
転移学習は非常に強力な手法であるが、使い方を間違えると「負の転移」と呼ばれる現象に悩まされることになる。これは、良かれと思って導入した外部の事前学習済みモデルが、自社の目的と合致していなかったために、かえって学習の邪魔をしてしまい、ゼロから学習させるよりも精度が悪くなってしまう現象を指す 。
負の転移を防ぐための鍵は、転移元(ソースドメイン)と転移先(ターゲットドメイン)の「性質の類似性」を見極めることにある。例えば、一般画像(犬、猫、車、風景など)で学習したモデルは、カラー画像における複雑な形状認識には強いが、これをそのまま「モノクロの透過X線画像から内部の気泡を見つける」といった、極めて微細な階調の差を判別するタスクに転用すると、元のモデルが持っている「鮮やかな色使い」や「背景の多様性」に関する知識がノイズとなり、判定精度が低下することがある 。
【製造現場における目的別検討事項とモデル選定】
技術者がAI導入を検討する際、目的に応じて以下のポイントを考慮する必要がある 。
1. 画像外観検査の導入
- 検討事項: 対象物が定型的か非定型的か。寸法測定や位置ズレならルールベース、感覚的な「良品感」や複雑なキズならAIベースが適する 。
- 技術的ポイント: 撮像条件(照明、カメラ位置)の安定化が最優先である 。照明が10%暗くなるだけでAIは「異常」と判定する可能性があるため、ハードウェア側の堅牢性が精度を左右する 。
- 転移学習の活用: 一般的な物体認識モデル(ResNetやEfficientNet等)をベースにしつつ、製造現場特有の「金属光沢」や「微細欠陥」に強いモデルを選定する 。
2. 機械の異常検知(振動・音・電流)
- 検討事項: 24時間監視が必要な回転機械(ファン、モータ等)において、どの程度の先行時間で異常を検知したいか 。
- 技術的ポイント: センサ設置位置の選定が重要。既存設備の4M(人、機械、材料、方法)管理に影響を与えず、かつノイズ(インバータ等)の影響を最小化する場所に設置する。
- 転移学習の活用: 音響データであれば音声認識モデルを、時系列データであれば時系列予測モデル(Transformer等)をベースとし、現場の正常稼働データで「正常の分布」を再定義する 。
3. 機械の予知保全(予兆管理)
- 検討事項: 「故障してから直す」事後保全から「故障の予兆を捉えて直す」CBM(状態基準保全)への移行によるROIの算出 。
- 技術的ポイント: 過去の故障実績データ(いつ、どの部品が、どのように壊れたか)と稼働データの紐付けが不可欠である 。
- 転移学習の活用: 類似機種の稼働履歴をベースモデルとし、自工場の稼働環境(湿度、気温、負荷等)に合わせて微調整を行う 。
自社のタスクと親和性の高い事前学習済みモデルを慎重に選定し、ドメイン間のギャップを認識することが、プロジェクトを成功に導く第一歩となる 。
第3章:巨大モデルをどう手なずける?ファインチューニングとリソース最適化
適切なモデルを選定した後は、自社のデータを読み込ませて微調整を行う「ファインチューニング」の工程に入る。しかし、近年のAIモデルは数百億規模のパラメータで構成されており、これら全ての数値を自社のデータに合わせて書き換えようとすれば、莫大なメモリと計算能力が必要になり、転移学習のメリットが薄れてしまう 。
このリソース問題を解決するための実践的な手法が、「浅い層のフリーズ(固定)」と「LoRA(低ランク適応)」である 。AIモデルは層状の構造をしており、入り口に近い「浅い層」はエッジや色といった基本的な特徴を、出口に近い「深い層」は具体的な対象物の意味を捉える役割を持っている 。転移学習では、基礎知識が詰まった浅い層は一切書き換えず(フリーズ)、出口に近い層だけを自社のデータに合わせて学習させることで、計算負荷を劇的に低減できる 。
さらに、最新の効率的な学習手法として注目されているのが「LoRA(追加ノート方式)」である。
表2:巨大モデルを手なずける微調整手法の比較表

LoRA(Low-Rank Adaptation)は、元の巨大なモデル(重み行列)を直接いじらず、学習によって変化する分だけを「小さな行列の積」として横に添える手法である 。数学的には、高次元の行列を低次元(低ランク)の行列に分解することで、更新すべきパラメータ数を数千分の一にまで圧縮する 。この手法により、一般的なPCや小規模なサーバー環境であっても、最先端の巨大モデルを自社専用にカスタマイズすることが可能になった 。
第4章:賢いAIが知識を忘れる?「破滅的忘却」を防ぐチューニングの極意
転移学習を進める中でエンジニアが直面するもう一つの課題が「破滅的忘却」である。これは、AIに新しい専門知識を詰め込もうとするあまり、モデルが元々持っていた汎用的で優秀な知能が上書きされ、消え去ってしまう現象を指す 。
例えば、一般的な日本語の文章作成がとても上手なAIに、自社特有の法律用語や契約書の書き方を教え込んだとします。学習が終わってテストしてみると、契約書の作成は完璧になったものの、なぜか普通の挨拶文すら不自然な日本語になってしまったり、一般的な常識を答えることができなくなったりすることがあります。新しい知識を詰め込む過程で、脳内のつながりが激しく書き換えられ、過去の優秀な知見が崩壊してしまった状態です。
破滅的忘却を防ぐためには、学習の設定(ハイパーパラメータ)を非常に繊細に調整する必要がある 。
- 学習率の極小化: AIが一度のデータ読み込みで脳内を書き換える「歩幅」を極端に小さく設定する 。転移学習はすでに完成に近い状態から始まるため、ミリ単位のすり足で慎重に調整を行うことが鉄則である。
- 既存データとの混合: 新しい専門データだけを見せるのではなく、元のモデルが学習に使ったような一般的なデータを時々混ぜて学習させる「リプレイ法」が効果的である 。
- 正則化の導入: 元の知識からあまりにも大きく離れた変化を起こした際、ペナルティを与える仕組みを導入し、既存の知能の構造を守る 。
これらの設定は表面には見えない数値だが、このバランス調整こそが、汎用的な賢さと専門的な鋭さを両立させるプロの技術といえる。
第5章:過学習を見抜き、AIを成長させ続ける「継続的運用サイクル」の構築
少量のデータで学習を行う転移学習において、最も警戒すべきは「過学習(オーバーフィッティング)」である 。これは、AIが学習データの「答えを丸暗記」してしまい、未知の新しいデータに遭遇した際に応用が効かなくなる状態を指す 。
過学習を見抜き、真の実力を測るためには「交差検証」という評価手法が不可欠である。手持ちのデータを「学習用」と「評価用」に分割し、データの組み合わせを変えながら何度もテストを繰り返すことで、特定の結果に偏っていないかを客観的に判断する 。また、実運用が始まってからがAI開発の本当のスタートである。製造現場の環境は刻一刻と変化する(照明の劣化、気温による部品の膨張、材料のロット差など) 。導入時には100%の精度が出ていたとしても、時間が経つにつれて徐々に精度が低下する「データドリフト」が発生する 。
この精度低下を防ぐためには、以下の「継続的改善サイクル」を回し続ける仕組みが必要である 。
- 判定データの自動蓄積: AIが判断に迷ったデータや、現場で誤判定が発覚したデータを自動的にクラウドやサーバーへ収集する 。
- 定期的アノテーション: 収集された「生きたデータ」に対し、熟練の技術者が正しい正解ラベルを付与する 。
- 再学習とモデル更新: 蓄積された新データを用いて再度ファインチューニングを行い、最新の環境に適応したバージョンへと更新する 。
転移学習の「少量のデータで素早く学習できる」という特性は、この頻繁なアップデートサイクルを回す上で非常に相性が良い。
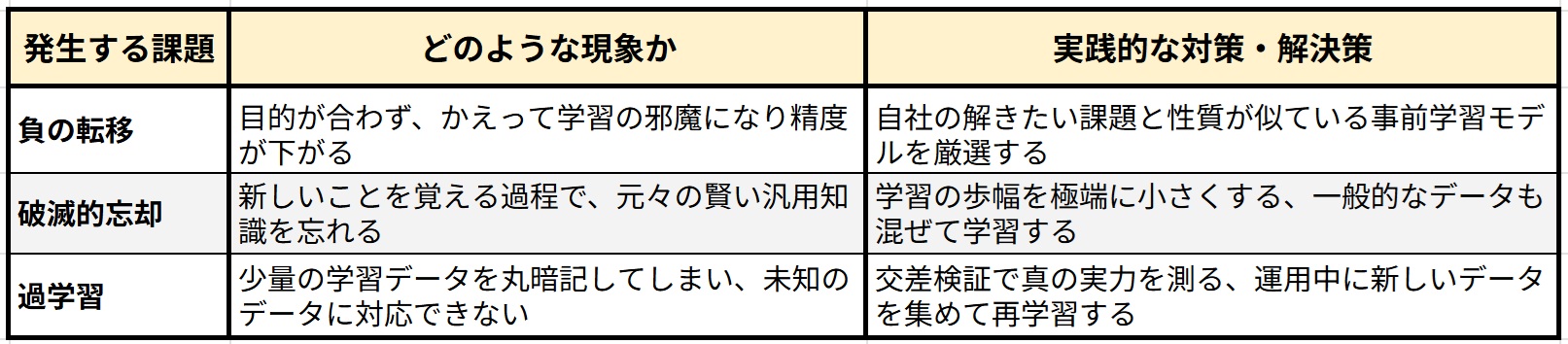
表3. 転移学習における3大課題と実践的な対策まとめ
第6章:RAG(検索拡張生成)の活用と、データ準備・評価の自動化技術
転移学習によるAI開発をさらに効率化し、開発・運用における現場の負担を軽減するためには、生成AIの一種であるRAG(検索拡張生成)の活用と、データ準備・評価の自動化技術を組み合わせることが非常に有効です。
RAG(検索拡張生成:Retrieval-Augmented Generation)とは、ChatGPTなどの大規模言語モデル(LLM)が、外部データベースから関連情報を検索し、その情報を基に回答を生成する技術です。AIが学習していない最新情報や、社内ドキュメントなどの秘密情報を活用でき、ハルシネーション(嘘の生成)を大幅に減らして回答の精度を高める手法として、AIの現場で主流となっています。以下に、開発時と運用時のフェーズに分けた具体的な軽減策を提案します。
1. 開発フェーズ:データ準備とモデル構築の負担軽減
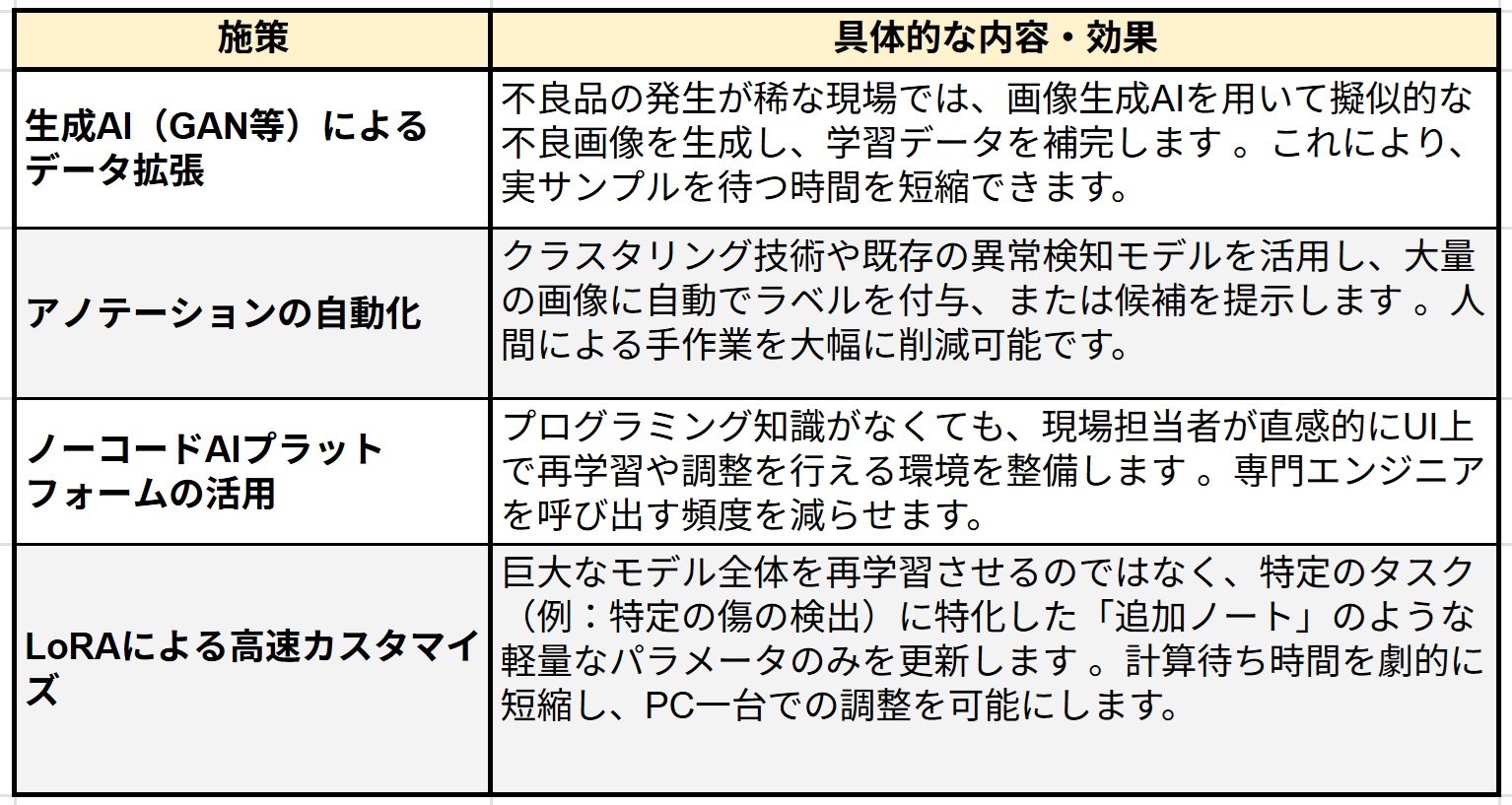
転移学習においても「少量の良質なデータ」は不可欠ですが、その収集やラベル付け(アノテーション)が現場の重荷となります。以下に4つの施策とお具体的な内容・効果について解説します。
表4. 4つの施策
2. 運用フェーズ:現場判断と維持管理の負担軽減
運用開始後、AIの「ブラックボックス化」や「属人化した知見の継承」が課題となります。ここでRAGが強力な力を発揮します。
表5.施策と効果

3. 教育・継承の負担軽減
RAGを活用した対話型システムを導入することで、新人教育や技能伝承のコストを削減できます。
- 技能伝承のデジタル化: 熟練技術者のノウハウが詰まった日報やメモをRAGの検索対象に含めることで、経験の浅い担当者でもAIに質問するだけでベテランに近い判断を下せるようになります。
- 新人教育のセルフサービス化: 新入社員が自力で疑問を解決できるようになり、教育担当者の負担が年間で大幅に削減された事例もあります。
これらの技術を組み合わせることで、AIを「高度な専門知識が必要なシステム」から、現場が「道具として使いこなせるサポーター」へと変えることが可能になります。
おわりに:小さく始めて大きく育てるAI開発へ
ここまで、転移学習の基本概念から、負の転移や破滅的忘却といった技術的な壁、そして運用サイクルの確立に至るまでを解説してきました。
「自社には大量のデータがないから」「高価なインフラ環境がないから」という理由でAIの活用を諦める時代は終わった。転移学習という「巨人の肩」に乗る手法を活用することで、限られたリソースであっても、目の前にある具体的な現場課題を解決することが可能になっている 。
成功の秘訣は、最初から完璧な万能AIを目指すのではなく、まずは特定のラインの、特定の不良検知といった「小さなテーマ」に絞ってスモールスタートすることである 。転移学習で迅速にプロトタイプを構築し、実際の運用現場で得られるフィードバック(生きたデータ)を糧にしてモデルを段階的に成長させていく。この「育てる」という感覚こそが、製造現場でAIを真の競争力へと昇華させるための最良のアプローチである 。
参考:技術的背景と理論の解説
本稿で解説した転移学習および効率的なAI開発を実現するための、より深い理論的側面をここにまとめる。技術者が詳細な設計やトラブルシューティングを行う際の指針として活用されたい。

3. 異常検知における PaDiM と FastFlow の理論
良品学習で用いられる代表的なアルゴリズムの仕組みは以下の通りである。
PaDiM (Patch Distribution Modeling): 画像をパッチ単位に分割し、事前学習済みモデル(CNN等)から抽出した特徴ベクトルを用いて、各パッチ位置の正常な多変量ガウス分布を推定する 。テスト画像が入力されると、マハラノビス距離を用いて分布からの外れ値を算出し、異常箇所を特定する 。
FastFlow: 正規化流(Normalizing Flow)という可逆なニューラルネットワークを用い、複雑な入力データの分布を単純な標準ガウス分布へと変換する 。異常データは変換後の空間において低確率領域に配置されるため、これを検知の基準とする 。
4. 説明可能AI(XAI)の活用:Grad-CAM
製造現場での信頼性を担保するために用いられる Grad-CAM (Gradient-weighted Class Activation Mapping) は、予測結果に対する最終畳み込み層の勾配情報を利用して、AIが画像の「どこ」を見て判定を下したかをヒートマップ化する技術である 。これにより、AIが本来見るべき製品の傷ではなく、背景や照明の反射に基づいて誤判定していないかを確認できる 。
5. 評価指標:再現率(Recall)と適合率(Precision)
製造現場では「見逃し(未検知)」を最小限に抑える必要があるため、再現率の最大化が優先されることが多い。しかし、再現率を高めすぎると「過検出(誤報)」が増え、現場の負担が増大する。このトレードオフを調整するために、F1スコアや PR曲線、AUC(曲線下面積)といった指標を用いて、実運用に最適な「判定しきい値」を決定するプロセスが必要となる 。