データサイエンスのビジネス活用が広まる中、最も活用されているものの1つが異常検知です。異常検知とは、膨大なデータの中から通常とは異なるものを特定すること、もしくはそのプロセスです。例えば、ECサイトをハッキングし不正な行動をする人は、通常の購入者と異なる購入パターン (購入金額や購入頻度、支払い方法、配送先住所、Cookieなど) を行う可能性があります。例えば、機器が故障する数日前から、機器内のセンサーデータのパターンが通常と異なる状態になる可能性があります。このような異常検知を、どのようなアルゴリズムで検出するのでしょうか。
日に数十レコードぐらいのデータ量であれば、人力でどうにかなるかもしれません。しかしデータ量が膨大で、数百万レコード、数十億レコードと、日々発生すると、人の目で見て判断するには限界があります。そのような場合、機械学習的なアプローチで実施するのが楽です。異常検知のアルゴリズムには色々ありますが、昔からあり比較的簡易なアプローチに、教師あり学習による異常検知と、教師なし学習による異常検知があります。今回は「教師あり異常検知と教師なし異常検知」というお話しをします。
【記事要約】
異常検知のアルゴリズム、簡易なアプローチである教師あり・なし学習による検知、このような異常検知を、どのようなアルゴリズムで検出するのか。データ量が膨大で、どのデータが異常で、どのデータが正常なのかラベリングされており、そのことから異常パターンがあらかじめ知りえるのであれば、教師あり学習による異常検知です。データ量が少なく、どのデータが異常で、どのデータが正常なのかラベリングされておらず、異常パターンが分からない場合には、教師なし学習による異常検知です。教師あり学習でしたらロジスティック回帰や決定木系など、教師なし学習でしたらクラスター分析や潜在クラス分析、混合正規分布モデルなどです。
1.「教師あり学習」と「教師なし学習」
機械学習では、「教師あり学習」と「教師なし学習」というワードがでてきます。教師あり学習とは、教師ラベル(目的変数y)が付いたデータセットを学習に利用する機械学習アプローチです。
(1)教師あり学習
多くの場合、教師ラベル(目的変数y)に「異常」or「正常」の値が入ります。もしくは、異常を複数の複数の分類もしくはレベル分類されている場合には、その異常の種類やレベルを示す値が入ります。
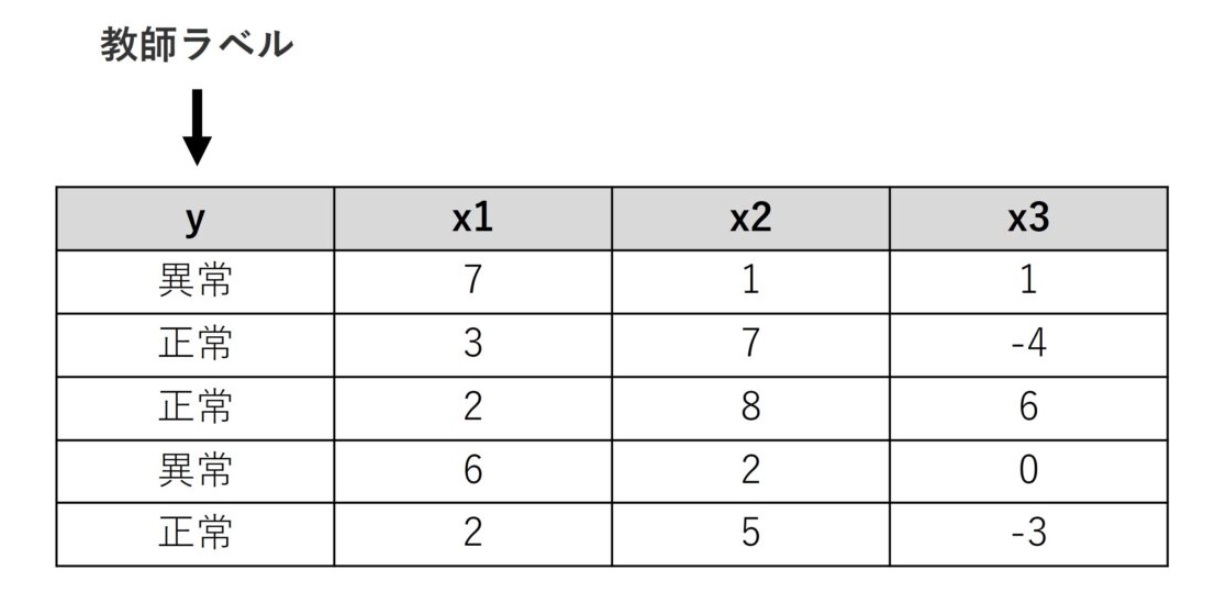
このような機械学習問題を、分類問題と表現したりします。この教師ラベル(目的変数y)をもとに、異常検知のためのモデルを構築します。子どもたちが、正解のあるドリルを使い学習するのに似ています。
(2)教師なし学習
一方、教師なし学習とは、教師ラベル(目的変数y)が付いていないデータセットを学習に利用する機械学習アプローチです。要は、教師ラベル(目的変数y)が無いため、どのレコードが正常で、どのレコードが異常なのかは、あらかじめ分かりません。この状態で異常検知のためのモデルを構築します。
2. 教師あり異常検知
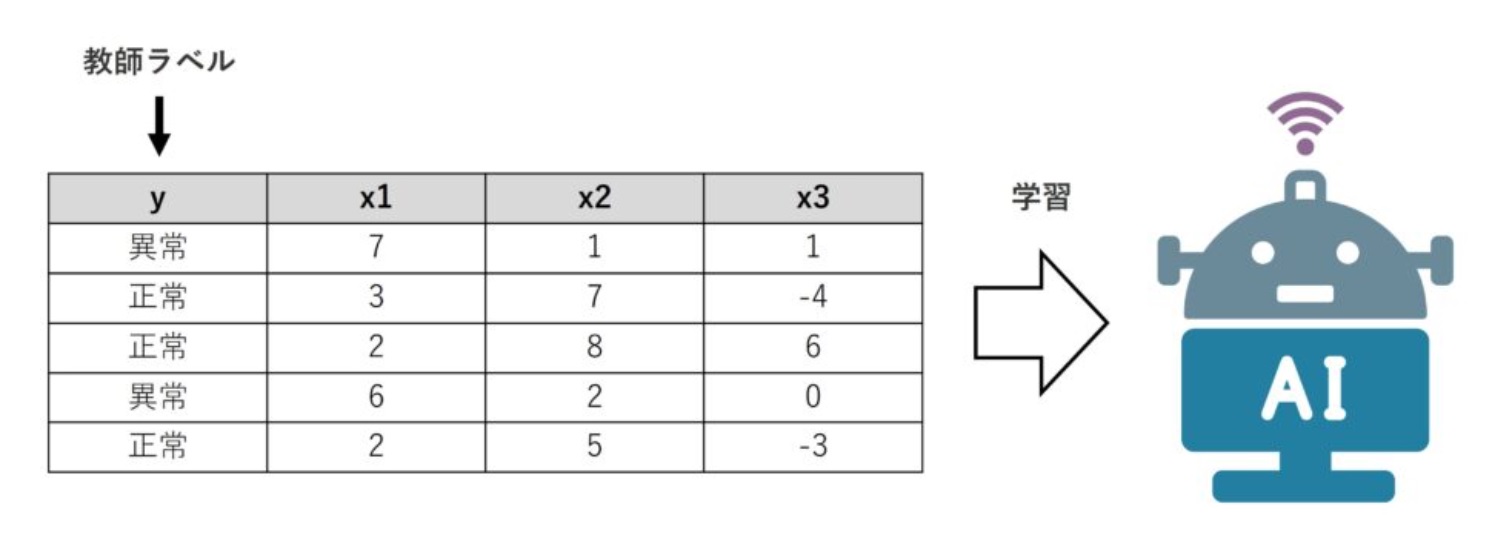
教師あり異常検知は、教師あり学習で構築した数理モデルを活用し、異常検知をするアプローチです。学習で使うデータに教師ラベル(目的変数y)があることで、異常パターンがどのようなものなのかを知ることができます。そのことから、新たに手にしたデータが、異常なのか正常なのかを分類することができます。一般的には分類問題と言われ、多くの数理モデルが提案されています。古典的には、ロジスティック回帰モデルや決定木系のモデルなどが有名です。
ただ、異常ラベルの付いたレコードと正常ラベルの付いたレコードが、バランスよく存在することは少なく、異常ラベルの付いたレコードが極端に少ないケースが多いです。そのため、異常ラベルの付いたレコードであるデータがある程度溜まるまで、データを蓄積し続けなければ、このアプローチは使えません。まとめると、教師あり異常検知は、異常パターンをあらかじめ知っていて、そのパターンに当てはまるかどうかを見ていく、ただしそのためにデータ量がすれなりに必要、そんな感じです。
3. 教師なし異常検知
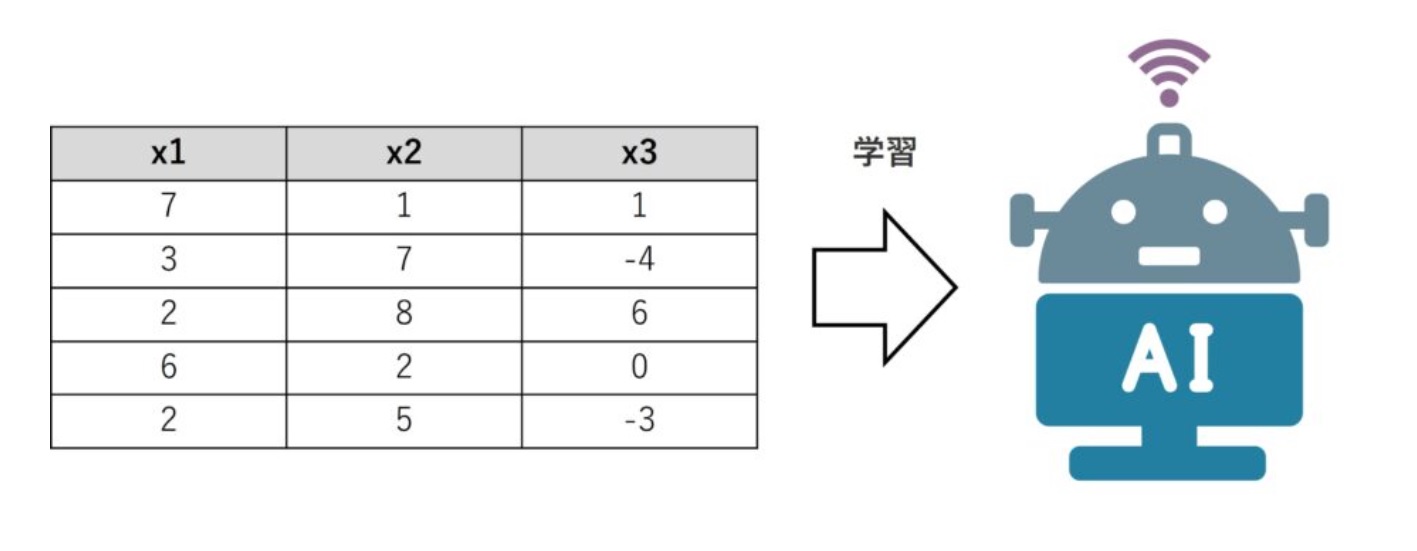
教師なし異常検知は、教師なし学習で構築した数理モデルを活用し、異常検知をするアプローチです。学習で使うデータに教師ラベル(目的変数y)がないため、異常パターンがどのようなものかを、事前に知ることはできません。しかし、ある1つのことは事前に知っています。それは、正常データと異なる、ということです。
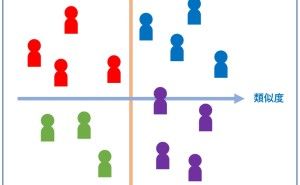
正常データと異なるため異常データと言われているので、当たり前と言えば当たり前ですが、そのことを利用します。そのため、手元に異常データがなくとも正常データさえあれば、異常検知をすることができ、学習データのデータ量も少なくてすみます。ちなみに、最もシンプルな方法は、似たようなパターンを持つレコードをグルーピングするクラスター分析を活用した方法です。
クラスター分析を実施したとき、異常データは...