管理図といえば、 通常はシュハートの3シグマ法 (シグマはここでは標準偏差の意味) をさしますが、そのことを知っている人から、逆に質問されたりすることがあります。
例えば-R管理図の管理限界に関して、単純に3シグマを計算した値とテキストの方法とでは一致しないというものです。
管理図の数理は、素直に標準的なテキストに従えば、難しくなく、むしろ、その見方 (運営) のほうが重要、かつ難しいと思われます。
ただ、基本的な数理の疑問があると、のどに刺さった骨のようで気持ちが悪いというひとのために、わかる範囲で説明します。特にここでは、 前述の-R管理図の
管理限界(非常に多い誤解)について説明します。 なお、標準偏差シグマや3シグマの基礎はわかってらっしゃるものとして進めます。 わかってらっしゃらない人は、素直に市販のテキストに従うので、 大きな疑問も誤解も生じないものと思われます。
【目次】
1. 単純な3シグマ計算と管理図数値表による係数からの管理限界の違いについての確認
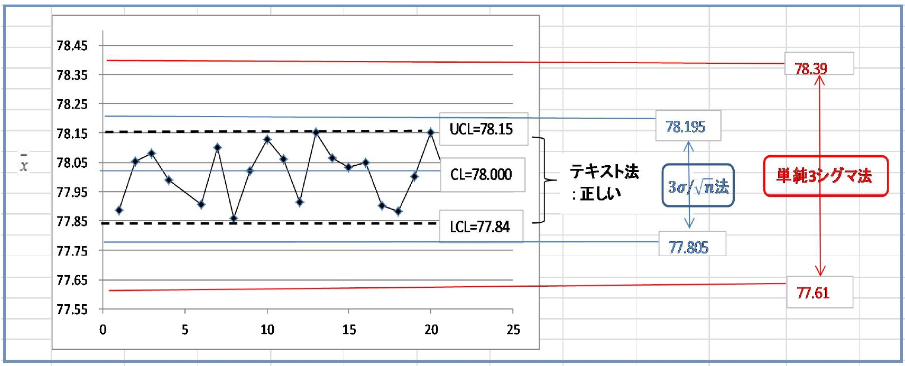
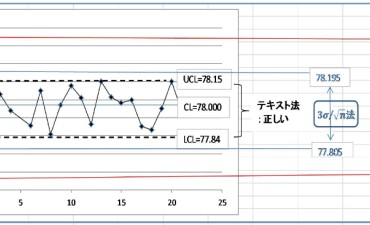
例として、群の大きさ n=4 (同一ロットあるいは製造日等)、群の数k=25、よって全データ数Nが100 のとき、平均値が 78 で標準偏差が 0.13 となった場合を想定します。
平均値±3シグマで、の管理限界を計算したとすると、78-3×0.13=77.61 から 78+3×0.13=78.39 までとなります。(ここで、この計算を単純3シグマ法と呼ぶことにします)
一方、管理図テキストの係数表、いわゆるA2をみると、A2=0.729。 =0.21 となったとして、 78-0.729×0.21=77.84 が下限で 78+0.729×0.21=78.15 が上限となります。 (ここではこの方法をテキスト法と呼びます) 単純に3シグマから計算した場合は、平均からの片幅が3×0....