
今、世界中で爆発的な広がりを見せる生成AI。私たちが日常でAIと対話するその裏側では、想像を絶する量のデータ処理が行われています。しかし、この進化において、「演算を行うチップ(GPU)」の性能向上だけでは対応しきれない深刻な問題が浮上しています。今回は、AIの進化を陰で支える立役者であり、半導体業界の勢力図を塗り替えつつある次世代メモリ「HBM(High Bandwidth Memory)」の全貌に迫ります。
【序章】 生成AI時代の新たな「産業の米」
1.ChatGPT等の登場による社会変革とGPUの限界
2022年、チャットGPTの登場は「IT革命」以来の衝撃を社会に与えました。文章生成、画像作成、プログラミングと、AIは人間の知的生産活動を代替・拡張し始めています。この巨大な知能を動かすエンジンの役割を果たしているのが、エヌビディア社のGPU(画像処理半導体)です。かつては半導体全体が「産業の米」と呼ばれましたが、今やその中心はAI向け半導体へとシフトしました。
しかし、どれほど高性能なエンジン(GPU)を積んでも、燃料(データ)がスムーズに供給されなければ、車は速く走れません。現在、AI開発の現場では、演算速度に対してデータの供給が追いつかないという事態が発生しています。これこそが、従来の技術だけでは解決できない壁です。
2.本稿の目的:AI進化の鍵を握る「HBM」の全貌を解き明かす
GPUの性能を極限まで引き出し、AIの更なる進化を可能にする鍵、それこそが「HBM(広帯域メモリ)」と呼ばれる特殊なメモリです。本稿では、なぜ今このメモリが不可欠なのか、どのような技術で成り立っているのか、そしてサムスン電子やSKハイニックスといった巨大企業たちが繰り広げる覇権争いの行方について解説します。これは単なる部品の話ではなく、AI時代の未来を決める最重要テクノロジーの物語です。
【第一章】 「メモリの壁」への挑戦~なぜ今、HBMなのか~
1.演算性能とデータ転送の不均衡
「メモリの壁」という言葉をご存じでしょうか。これは、プロセッサ(計算する頭脳)の計算速度が劇的に向上する一方で、メモリ(データを記憶し渡す場所)からデータを読み書きする速度の向上が追いつかず、システム全体の性能向上が頭打ちになる現象を指します。
これを「高速道路と入り口」の関係で例えてみましょう。GPUという名のスポーツカーは、時速数百キロで走れる圧倒的なエンジン性能を持っています。しかし、そのスポーツカーが走るための燃料や荷物(データ)を運び込むための「入り口(メモリの転送速度)」が狭く、渋滞を起こしている状態が現在の姿です。どんなに車が速くても、入り口で何時間も待たされては意味がありません。従来のメモリ技術では、AIが必要とする膨大なデータを、GPUが求めるスピードで供給することが物理的に不可能になってしまったのです。
2.LLMが求める圧倒的な帯域幅
現在、AI開発の主流である「大規模言語モデル(LLM)」は、その名の通り「大規模」であることが性能の源泉です。エヌビディアの最新鋭チップ「H100」や「B200」といったモンスター級のGPUは、一度に処理するデータ量が桁違いです。
AIの賢さを示す指標の一つに「パラメータ数」がありますが、これは数千億、数兆という単位に肥大化しています。AIが質問に答えたり(推論)、新しい知識を覚えたり(学習)...
今、世界中で爆発的な広がりを見せる生成AI。私たちが日常でAIと対話するその裏側では、想像を絶する量のデータ処理が行われています。しかし、この進化において、「演算を行うチップ(GPU)」の性能向上だけでは対応しきれない深刻な問題が浮上しています。今回は、AIの進化を陰で支える立役者であり、半導体業界の勢力図を塗り替えつつある次世代メモリ「HBM(High Bandwidth Memory)」の全貌に迫ります。
【序章】 生成AI時代の新たな「産業の米」
1.ChatGPT等の登場による社会変革とGPUの限界
2022年、チャットGPTの登場は「IT革命」以来の衝撃を社会に与えました。文章生成、画像作成、プログラミングと、AIは人間の知的生産活動を代替・拡張し始めています。この巨大な知能を動かすエンジンの役割を果たしているのが、エヌビディア社のGPU(画像処理半導体)です。かつては半導体全体が「産業の米」と呼ばれましたが、今やその中心はAI向け半導体へとシフトしました。
しかし、どれほど高性能なエンジン(GPU)を積んでも、燃料(データ)がスムーズに供給されなければ、車は速く走れません。現在、AI開発の現場では、演算速度に対してデータの供給が追いつかないという事態が発生しています。これこそが、従来の技術だけでは解決できない壁です。
2.本稿の目的:AI進化の鍵を握る「HBM」の全貌を解き明かす
GPUの性能を極限まで引き出し、AIの更なる進化を可能にする鍵、それこそが「HBM(広帯域メモリ)」と呼ばれる特殊なメモリです。本稿では、なぜ今このメモリが不可欠なのか、どのような技術で成り立っているのか、そしてサムスン電子やSKハイニックスといった巨大企業たちが繰り広げる覇権争いの行方について解説します。これは単なる部品の話ではなく、AI時代の未来を決める最重要テクノロジーの物語です。
【第一章】 「メモリの壁」への挑戦~なぜ今、HBMなのか~
1.演算性能とデータ転送の不均衡
「メモリの壁」という言葉をご存じでしょうか。これは、プロセッサ(計算する頭脳)の計算速度が劇的に向上する一方で、メモリ(データを記憶し渡す場所)からデータを読み書きする速度の向上が追いつかず、システム全体の性能向上が頭打ちになる現象を指します。
これを「高速道路と入り口」の関係で例えてみましょう。GPUという名のスポーツカーは、時速数百キロで走れる圧倒的なエンジン性能を持っています。しかし、そのスポーツカーが走るための燃料や荷物(データ)を運び込むための「入り口(メモリの転送速度)」が狭く、渋滞を起こしている状態が現在の姿です。どんなに車が速くても、入り口で何時間も待たされては意味がありません。従来のメモリ技術では、AIが必要とする膨大なデータを、GPUが求めるスピードで供給することが物理的に不可能になってしまったのです。
2.LLMが求める圧倒的な帯域幅
現在、AI開発の主流である「大規模言語モデル(LLM)」は、その名の通り「大規模」であることが性能の源泉です。エヌビディアの最新鋭チップ「H100」や「B200」といったモンスター級のGPUは、一度に処理するデータ量が桁違いです。
AIの賢さを示す指標の一つに「パラメータ数」がありますが、これは数千億、数兆という単位に肥大化しています。AIが質問に答えたり(推論)、新しい知識を覚えたり(学習)する際、この膨大なパラメータデータを瞬時にメモリからGPUへ送らなければなりません。もし転送が遅れれば、チャットボットの回答が極端に遅くなったり、学習に数ヶ月余計にかかったりします。この「待ち時間」を極限までゼロに近づけ、GPUを常にフル回転させるために、圧倒的な広さを持ったデータの通り道(帯域幅)が必要とされているのです。
【第二章】 平面から立体へ~HBMを支える技術革新~
1.従来のDRAM・GDDRとの決定的違い
これまでパソコンやゲーム機のグラフィックボードで使われてきた「GDDR」というメモリは、いわば「平屋建て」の住宅地でした。チップを平面上の基板に並べて配置するため、データをやり取りする配線の数や距離に物理的な制約があります。土地(基板面積)も多く必要とし、信号を送る距離が長くなるため電気も多く消費します。
対して、HBM(ハイ・バンハドウィズ・メモリ)の発想は、都心の「超高層ビル」です。限られた土地の中で収容力を増やし、移動距離を短くするために、メモリチップを上に何層も積み上げる構造を採用しました。これにより、わずかな面積で大容量を実現し、かつてない速度でのデータ転送を可能にしました。
2.核心技術「TSV(シリコン貫通電極)」と「3Dスタッキング」
では、積み上げたチップ同士をどうやって繋ぐのでしょうか。この積層構造を実現する基幹技術が「TSV(シリコン貫通電極)」です。これは、薄く削ったシリコンチップ自体に数千個もの微細な穴を垂直に開け、そこに電気を通す柱を埋め込む技術です。
従来の方式が、建物の外側に非常階段をつけて各階を行き来していたとするなら、TSVはチップ内部を垂直に貫通する電極を配置する手法で、例えるなら建物の中心に多数の高速エレベーターを設置するような構造です。これにより、チップの各層を最短距離で、しかも大量に直結することが可能になります。
この技術により、HBMはデータの通り道(バス幅)を、従来のGDDRの数十倍である「1024」という広さにまで拡張しました。これは、細い路地だった道路が一気に千車線の超巨大道路になったようなものです。さらに、チップ同士の距離が極めて近いため、データを送るための電力が少なくて済み、熱の発生も抑えられるという、省エネ面での大きなメリットも生まれています。
【第三章】 主要メーカー3社による開発競争と市場シェアの推移
1.先駆者 SKハイニックスの独走
現在、HBM市場で圧倒的な強さを見せているのが、韓国のSKハイニックスです。彼らはAIブームが到来する遥か前からこの技術に投資し、エヌビディアとの強固なパートナーシップを築いてきました。
彼らの独走を支えているのが「MR-MUF」という独自技術です。これは、積み上げたチップの隙間に特殊な液体材料を流し込んで固める手法で、熱を逃がす効率が良く、生産時の不良品発生率(歩留まり)を低く抑えることができます。エヌビディアの最高峰GPUにいち早く採用された実績が、彼らを「HBMの王者」へと押し上げました。
2.巨人 サムスンの焦りと巻き返し
一方、メモリ業界全体の王者である韓国のサムスン電子は、HBMに関しては後手に回りました。長年トップに君臨してきたプライドが、AI特需への反応を鈍らせたとも言われています。
サムスンは「TC-NCF」という、チップの間にフィルムを挟んで熱圧着する技術を採用していますが、積層数が増えるにつれて製造が難しくなり、品質認定のプロセスで苦戦を強いられました。しかし、世界一の生産能力と資金力を持つ巨人が黙っているわけではありません。技術改良を急ピッチで進め、次世代品での逆転を虎視眈々と狙っています。
3.マイクロンの戦略的ニッチと追い上げ
アメリカのマイクロン・テクノロジーは、韓国勢2社に続く3番手ですが、したたかな戦略をとっています。彼らは最新規格「HBM3E」において、競合よりも「電力効率」が良いことを猛アピールしています。
AIデータセンターにおいて、膨大な電力消費は深刻な課題です。「性能は同等以上で、電気代が安い」という特徴は、顧客にとって大きな魅力です。マイクロンはこの一点突破でシェアを奪い始めており、三つ巴の戦いは激化の一途をたどっています。
【第四章】 作りたくても作れない~製造の複雑さと「CoWoS」の壁~
1.HBMは単体では動かない
HBMは、単にパソコンのメモリ差し込み口に挿せば使えるものではありません。HBMの性能を発揮させるには、GPUのすぐ隣、髪の毛の太さほどの距離に配置し、極めて精密な配線で繋ぐ必要があります。
そのために行われるのが「2.5次元パッケージング」という手法です。GPUと複数のHBMを、まず「インターポーザ」と呼ばれる一枚の大きなシリコン基板の上に載せ、その全体を一つのパッケージとして組み立てます。つまり、GPUとHBMは「同じ基板に住む同居人」としてセットで作られるのです。
2.ボトルネックとしての「CoWoS」
ここで問題となるのが、世界最大の半導体製造受託会社である台湾TSMCが持つ「CoWoS(コワース)」というパッケージング技術の生産能力です。
AIチップが不足している原因は、実はGPU自体の製造よりも、この「GPUとHBMを合体させる工程」のキャパシティ不足にあります。土台となるシリコンインターポーザは面積が大きく、製造が非常に難しい上、非常に割れやすいのです。また、狭い空間に高発熱なGPUと熱に弱いメモリを押し込めるため、熱をどう逃がすかという物理的な限界との戦いでもあります。HBMの供給能力だけでなく、それらをGPUと統合するインターポーザ(中継基板)を含むパッケージング工程のキャパシティが、システム全体の供給量を左右する要因となっています。
【第五章】 次世代「HBM4」とカスタム化する未来
1.HBM4がもたらすパラダイムシフト
技術の進化は止まりません。2026年頃の量産が予定されている次世代規格「HBM4」では、さらなるパラダイムシフトが起きます。データの通り道は現在の2倍(2048ビット)に広がり、積層数も12段から16段へと高層化が進みます。
これにより、一つのHBMで扱えるデータ量と速度は劇的に向上し、より巨大で複雑なAIモデルを動かすことが可能になります。まさに「摩天楼」のようなメモリが誕生しようとしています。
2.汎用品から「カスタムHBM」へ
HBM4時代には、メモリの「作り方」も変わります。これまでは規格通りの「汎用品」を買ってくるのが当たり前でしたが、グーグルやメタといった巨大IT企業は、自社のAIに最適化した「カスタムHBM」を求め始めています。
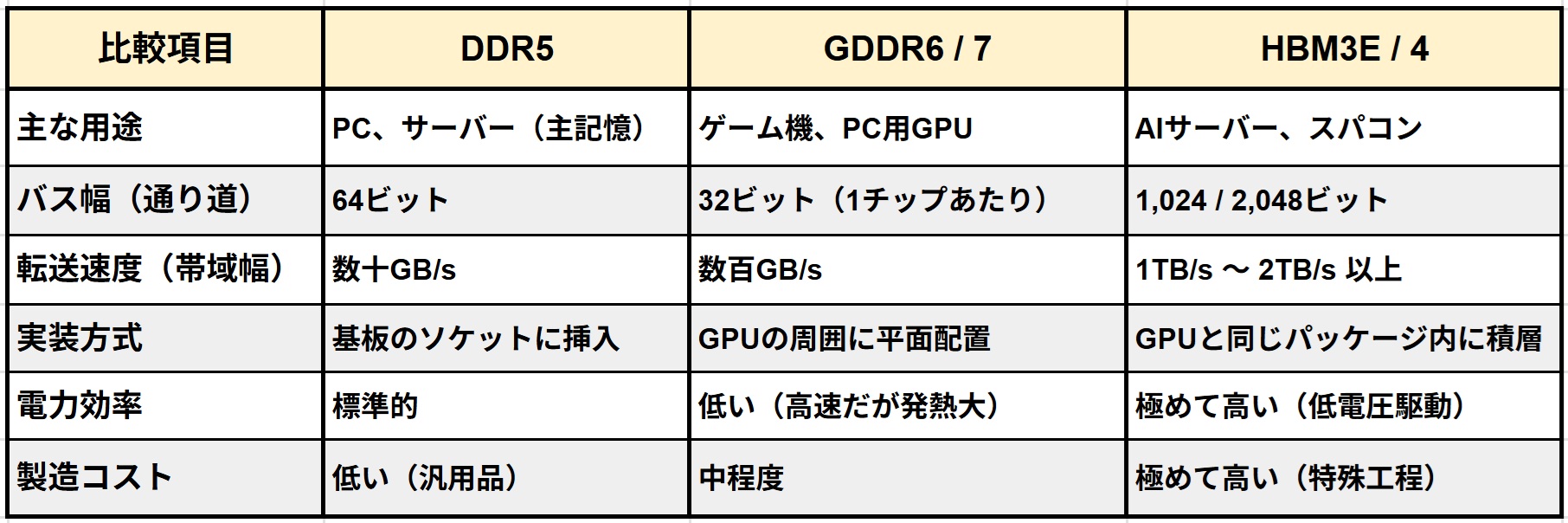
具体的には、HBMの一番下の土台部分(ベースダイ)に、簡単な計算機能などのロジック(論理回路)を組み込む計画が進んでいます。メモリ自身が少し賢くなり、GPUの負荷を減らすのです。また、チップ同士をハンダの突起なしで直接貼り合わせる「ハイブリッド接合」という超難度の技術も導入され、ロジック層を含むベースダイの設計において、メモリメーカーとファウンドリの密接な協調体制(デザイン連携)が不可欠となります。下表から、メモリー規格性能比較をご覧ください。
表.メモリー規格性能比較表
【終章】 演算性能のその先へ
HBMの進化を見てくると、メモリはもはや単なる「データの保管庫」ではなく、「演算システムの一部」として融合しつつあることが分かります。GPUというエンジンの性能を活かすも殺すも、HBMという燃料供給システムの進化次第です。AIが私たちの想像を超えて進化できるかどうか、その命運は、この小さなシリコンの積層技術にかかっていると言っても過言ではありません。























