最近はテレビや新聞でも人工知能(AI)、IoT、ビッグデータという言葉が当たり前のように使われるようになりました。僕が勤める会社でもそれに関連してなのか、データ解析(Analytics )分野の研究や製品開発が進んでいます。リーンシックスシグマも例外ではありません。もしかしたら今後、リーンシックスシグマが人口知能を取り入れていくかもしれません。いやむしろ、人口知能が時代遅れのリーンシックスシグマに取って代わってしまうかもしれません。そんな危機感もあり、今回は人工知能の中でも特に機械学習についてです。
まず、色々と機械学習に関連した本やサイトを読んでいて感じたことは、次の3点です。
- 機械学習で使っている言葉はリーンシックスシグマとは違うけれど、やっていること自体はそれほど違いがない
- リーンシックスシグマの知識と経験があれば、機械学習に十分対応できる
- リーンシックスシグマの実務者にとって、機械学習、恐るるに足らず
結論から先に言えば、「リーンシックスシグマは時代の先を走っていたのか」と僕には思えました。
1. リーンシックスシグマによるシステムの最適化
リーンシックスシグマでは、対象とするシステム(生産システム、事務処理、製品設計、品質など)が複雑過ぎてよく分からない(ブラックボックス化されている)とき、DOE(Design of Experiments 実験計画法)を使って、そのシステムを理解しようとします。システムを理解しない限り、システムの最適化やシステムの向上が図れないからです。
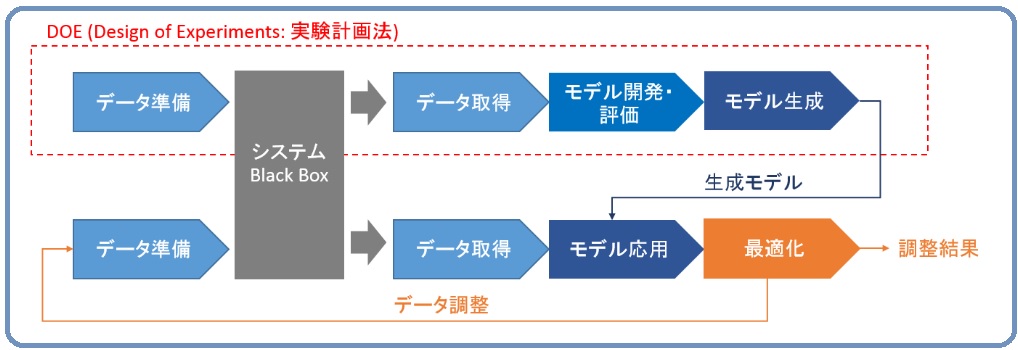
(1) データの準備
DOE では解析に必要となるデータ(入力パラメータ)をあらかじめ準備します。次のステップである「データの取得」は時間やコストがかかるため、それを少しでも削減するために、統計的に意味のある入力パラメータを準備します。
(2) データの取得
準備したデータをシステムに与えます。「システムのパラメータを計画的に変更する」と言った方が正確かもしれません。そしてその結果(出力)をシステムから取得します。
(3) モデルの開発と評価
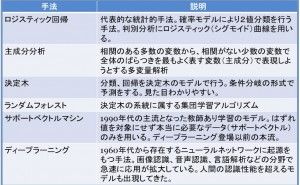
システムへの入力値と、それに応じたシステムからの出力を使って、統計的にシステムをモデル(数式)化します。モデル化に使う統計的手法としては、線形や非線形の重回帰分析や、ロジスティック回帰分析などがあります。
(4) モデルの生成
主要因子だけを使ったモデル(数式)によってシステムを表現します。
(5) モデルの応用
モンテカルロ・シミュレーションなどにモデルを与え、システムの能力や可変性などを評価します。実際のシステムにおいて入力パラメータをどれだけ変更できるのかなど、その調整範囲なども確認します。
(6) 最適化
システムからの出力が最適になるよう、入力パラメータを調整します。最適化には線形計画法や非線形計画法などを使います。そして調整した入力パラメータをシステムに与え、後は実際のシステムからの出力が最適になるまで、その処理を繰り返します。
(1)~(6)が DOE を使ったリーンシックスシグマによるシステム最適化の大体のやり方です。
2. 機械学習によるシステムの予測
リーンシックスシグマと異なり、機械学習はシステムを良くするためのツールではありません。一方リーンシックスシグマと同様に、機械学習は分からないシステムを理解するためのツールだと言えます。それは最終的な目的が、リーンシックスシグマの場合はシステムの最適化であり、機械学習の場合はシステムの予測であることからも分かります。
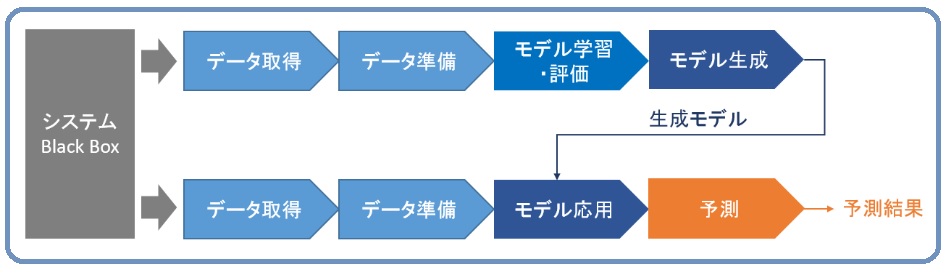
(1) データの取得
大量のデータ(所謂ビッグデータ)をシステムから取得します。IoT による装置からのデータ取得であったり、マーケティングによる市場からのデータであったりします。
(2) データの準備
リーンシックスシグマの DOE とは違い、統計的に計画して取得したデータではないので、雑多なデータが混ざり込んでいます。それを統計処理ができるようになるまで、取得したデータを綺麗に整理します。
(3) モデルの学習と評価
統計処理が可能なように準備されたデータを使って、システムをモデル(数式)化します。モデル化に使う統計的手法としては、リーンシックスシグマでも良く使う線形・非線形の重回帰分析、ロジスティック回帰分析などの他に、ナイーブベイズ分類、サポートベクターマシン、K-平均法などがあります。
(4) モデルの生成
色々な統計的手法を試してみて、最終的にもっとも良くシステム(入力データに対する出力結果)を説明できるモデルを生成します。
(5) モデルの応用
新たにデータを取得して、生成したモデルに与えます。
(6) 予測
新たなデータを使って、モデルにより結果を予測します。
上記二つの図を比べると、DOE を使ったリーンシックスシグマも、機械学習も、そのプロセスはとても良く似ていることが分かります。実際にリーンシックスシグマで使う統計処理ツール(例えば Minitab や MATLAB、R など)が機械学習でも使えますし、使う統計処理も良く似ています。機械学習で使うビッグデータの場合は、データ数が多い分、統計的な制約が少ないため処理が簡単な場合もあります。
両者の違いは、リーンシックスシグマがシステムの入力パラメータを変えることを前提とした「システム...