
 データマイニングは、大量のデータから有用な知識・情報を取り出す技術のことです。マイニングとは、鉱山から鉱物を掘り出す作業のことで、あたかもデータの山から、知識・情報を掘り当てる技術に例えられます。データマイニングには、主に統計解析、機械学習、人工知能などが用いられます。
データマイニングは、大量のデータから有用な知識・情報を取り出す技術のことです。マイニングとは、鉱山から鉱物を掘り出す作業のことで、あたかもデータの山から、知識・情報を掘り当てる技術に例えられます。データマイニングには、主に統計解析、機械学習、人工知能などが用いられます。◆ビッグデータとデータマイニング
データマイニングは、大量のデータから情報を取り出す技術です。今までにも知られていた技術ですが、大量データを用いる時代になって再び注目されるようになっています。例えば、(1)twitterやFacebookなどの大量のウェブログデータ、(2)センサーなど各種計測機器をインターネットに接続することによって得られた計測データ、センサーデータ、制御データを通信するIoT(Internet of Things:物のインターネットなど)の大規模データから情報を収集するようになりその要望が増えています。ビッグデータを扱う需要が増えてきており、そのデータ分析を行う分野であるデータサイエンスに注目が集まっています。
データマイニングと似た言葉に、機械学習があります。データを反復的に学習し、そこに潜むパターンを見つけ出すこと、とされています。実際には、機械学習には、スパムメールフィルタなど、あらかじめ紐付けされた情報が与えられ、そこから共通するパターンを見出し、そのパターンに基づいて別の新たなデータを識別する教師付き学習と、与えられた大量の情報を共通する規則に基づいて分類する教師なし学習があります。データマイニングで使われる技術と機械学習で使われる技術は共通する部分が多く、大量のデータから情報を抽出するという行為に注目した言葉がデータマイニングで、そのアルゴリズムや分析技術に注目した言葉が機械学習ということもできます。
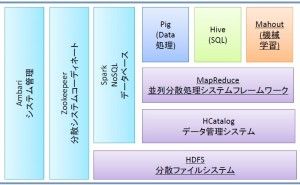
近年、数ギガバイトないし、それをはるかにしのぐテラバイト級(テラはギガの1000倍)、ペタバイト級(ペタはテラの1000倍)、あるいはさらに大きなエクサバイト級(エクサはペタの1000倍)のデータの情報分析を行うようになり従来のデータベースなどでは処理しきれないデータを扱う特殊な技術が用いられるようになりました。
例えば、一台のハードディスクに収まりきらないファイルを複数のコンピュータからなるコンピュータクラスタに分散して保存する分散ファイルシステム(HDFSが代表的な技術です)、一個のCPUで処理しきれない大量の計算プロセスを複数のコンピュータからなるコンピュータクラスタに分散して処理する分散処理システム(MapReduceが代表的な技術です)などです。さらに、分散処理...




















-守・破・離ー")

-その原点を考える")



