

◆ 分析は最終的かつ不可逆的なもの
蓄積され続けてはいるけど、人手にあまり触れられていないデータの中には、データの粒度がバラバラなケースが多々みられます。そのようなデータを相手に集計や分析を行うと非常に苦労します。ちなみに、データの粒度とはデータの細かさの程度をいいます。分かりやすくお話すると時間やカテゴリー、エリアなどです。例えば時間の粒度がバラバラとは、あるデータは日単位で、あるデータは月単位であるということです。
カテゴリーの粒度がバラバラとは、エリアや時期によってデータとして蓄積されているカテゴリーが異なったり(ある時期は大カテゴリーまでのデータしかない、など)、カテゴリーの分け方(考え方)が異なるということです。
今回は「分析は最終的かつ不可逆的なので、データの粒度はより細かく」というお話しをします。
【目次】
- 加工は「不可逆的」
(1)粗い粒度を細かくできない
(2)モデルを構築した時、使用した学習データは、モデルからは分からない
(3)覆水盆に返らず - データの粒度はより細かく蓄積しておこう
- 今回のまとめ
1. 加工は「不可逆的」
不可逆的とは、加工する(手を加える)と元に戻せない性質のことを意味します。例えば、工場で物を生産するとき、機械などで加工しますが、一度材料などに手を加えると元の状態に戻すことができなくなります。データの集計や分析なども同様です。
(1)粗い粒度を細かくできない
1日単位のデータを1ケ月単位に集計するなど、細かい粒度のデータを粗くすることは可能です。しかし逆は非常に難しくなります。要するに、粗い粒度を細かくできないのです。
(2)モデルを構築した時、使用した学習データは、モデルからは分からない
データ分析・活用をビジネスで実施しようとする時、異常検知や予測モデルなどを構築することはあります。これらモデルを構築するためにはデータが必要になります。そのようなデータを、学習データといいます。当然ですが、モデルを構築した時に使用した学習データは、モデルからは分かりません。
(3)覆水盆に返らず
データ分析も最終的かつ不可逆的なため、後から粒度の粗いデータを細かくできないし、構築されたモデルから学習データを作ることはできません。要するに「覆水盆に返らず」です。もし、データの粒度が粗い状態で蓄積されていたら最終的かつ不可逆的と諦(あきら)め、その範囲でどうにかして、データ分析・活用をしなければなりません。
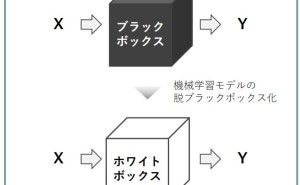
ブラックボックス化された異常検知や予測モデルなどを使うのであれば最終的かつ不可逆的と諦め、その状態でデータ分析・活用をしなければなりません。つまり、取り返しがつかないということです。ここで悩んでも仕方がないので、現状でどうにかする必要があります。さらに、今後悩まないように、データ分析も最終的かつ不可逆的であることを前提に、データ分析・活用を考えていく必要はあります。
2. データの粒度はより細かく蓄積しておこう
可能ならば、データの粒度はより細かく蓄積しておいたほうがいいでしょう。
今不必要な粒度でも、将来必要な粒度になることはあります。また、利用している数理モデルを構築した時の学習データなども残しておきましょう。その時学習データだけでなく、どのように学習させたかという条件設定や、そこに至るまでのフローなども残しておいたほうがいいでしょう。残念なことに、数理モデルを構築したときの学習データと思われるもので、数理モデルを再構築したのに再現できない、ということがたまにあります。
3. 今回のまとめ
今回は「データの粒度はより細かく、なぜならばデータ分析は最終的かつ不可逆的だから」というお話しをしました。
それなりのデータ分析をしたことのないデータの場合、データの粒度がバラバラで苦労することがあります。データの粒度とは、文字通りデータの細かさの程度をいい、時間やカテゴリー、エリアなどです。例えば、1日単位のデータを、...











































































































































































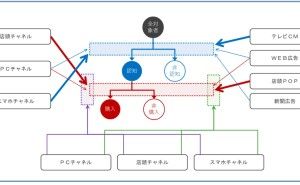
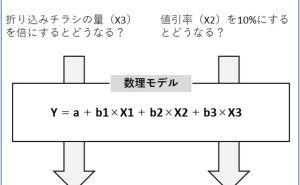
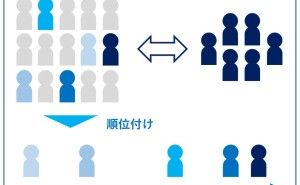
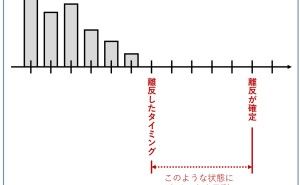

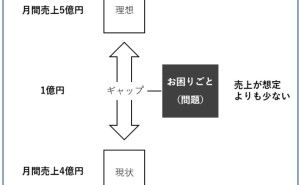



























































































実践Rケモ・マテリアル・データサイエンス ~ 付録Rスクリプト付き ~")



