-

マテリアルズインフォマティクスのためのデータ解析
全国55,0002024-05-31 -

ベイズ最適化による実験計画法の基礎と具体的すすめ方
全国47,3002024-05-23 -

実験計画法のポイント
11,000オンデマンド -
熱分析の基礎と測定・解析技術
全国55,0002024-05-10 -

マテリアルズ・プロセスインフォマティクスの基礎とポリマー材料設計への応用
全国49,5002024-05-29 -

化学分析担当者が知っておくべき分析データの取り扱い基礎講座
全国55,0002024-05-22 -
品質統計解析の分析法バリデーションへの応用
41,800オンデマンド


材料開発のためのデータ解析入門
化学・産業データの使い方、解析の仕方を基礎から解説
情報科学・データサイエンスに基づき、
種々の材料の機能を予測するモデルの構築などを学ぶ
ケモインフォマティクス・マテリアルズインフォマティクス・プロセスインフォマティクス分野を中心に豊富な応用事例も紹介
セミナー趣旨
近年、化学の分野や産業全般においてデータが蓄積されつつあり、そのデータを解析する動きが活発になっている。例えば高機能性材料を開発する際、化合物データを用いて化学構造と物性・活性・特性との間の関係をモデル化することで、化合物を合成したり合成後に物性値を測定したりする前に、化学構造から物性値を推定でき、逆に良好な物性値をもつ化学構造の設計もできる。さらに、製造条件とその製造の結果としての製品品質との間の関係をデータからモデル化することで、望ましい品質を達成するための製造条件を探索できる。高機能性材料を製造する際、センサー等で容易に測定可能なプロセス変数と測定が困難な製品品質との関係をデータからモデル化することで、製品品質の値をリアルタイムに推定し、迅速かつ安定に制御・管理ができる。このように、高機能性材料などの開発データ、化学・産業プラントにおける運転データなど、蓄積されたデータは非常に有用であるが、十分に活用しきれていない。本セミナーでは、化学・産業データの使い方・解析の仕方を基礎から解説する。情報科学・データサイエンスに基づき、データから種々の材料の機能を予測するモデルを構築したり、構築したモデルを活用することで新たな構造・実験条件・材料・装置を設計したりする方法を説明する。さらに、ケモインフォマティクス・マテリアルズインフォマティクス・プロセスインフォマティクス分野を中心にして豊富な応用事例も紹介する。
受講対象・レベル
・化学・産業界において、インフォマティクスを活用して材料開発(および化学品開発)に従事している研究者・技術者
・材料開発(および化学品開発)にインフォマティクスを今後活用しようと考えている研究者・技術者
習得できる知識
・ケモインフォマティクス・マテリアルズインフォマティクス・プロセスインフォマティクス・データ解析・機械学習・分子設計・材料設計・プロセス設計・プロセス管理の基礎知識
・ケモインフォマティクス・マテリアルズインフォマティクス・プロセスインフォマティクス分野の最新の研究事例
・データ解析の一般的なすすめ方・活用の仕方 ・データ解析の応用事例 ・最新のデータ解析手法・モデリング手法 ・モデルの予測精度向上の方法 ・モデルの逆解析の方法
セミナープログラム
1. ケモインフォマティクス・マテリアルズインフォマティクス・プロセスインフォマティクスの基礎知識
1.1. 機械学習・人工知能
1.2. 定量的構造物性相関・定量的構造活性相関
1.3. 化学構造生成
1.4. 分子設計
1.5. 材料設計
1.6. プロセス設計
1.7. プロセス管理
1.8. ケモインフォマティクス
1.9. マテリアルズインフォマティクス
1.10. プロセスインフォマティクス
2. 化学・産業データ解析の進め方・活用方法
2.1. データの形式、記述子
2.2. データの前処理
2.2.1. 標準化
2.2.2. 変数選択
2.2.3. スムージング (平滑化)
2.3. データの可視化・低次元化
2.3.1. 主成分分析 (Principal Component Analysis, PCA)
2.3.2. Generative Topographic Mapping (GTM)
2.3.3. 多様体学習
2.3.4. 可視化の性能を検討するための指標
2.4. クラスタリング
2.4.1. 階層的クラスタリング
2.4.2. k平均法 (k-means)
2.4.3. 混合ガウスモデル (Gaussian Mixture Model, GMM)
2.5. クラス分類
2.5.1. 線形判別分析 (Linear Discriminant Analysis, LDA)
2.5.2. 決定木 (Decision Tree, TD)
2.5.3. ランダムフォレスト (Random Forest, RF)
2.5.4. サポートベクターマシン (Support Vector Machine, SVM)
2.6. 回帰分析
2.6.1. 最小二乗法による重回帰分析 (Multiple Linear Regression (MLR) or Ordinary Least Squares (OLS) )
2.6.2. 部分的最小二乗法 (Partial Least Squares, PLS)
2.6.3. 決定木 (Decision Tree, DT)
2.6.4. ランダムフォレスト (Random Forest, RF)
2.6.5. サポートベクター回帰 (Support Vector Regression, SVR)
2.7. モデルの予測性能の向上
2.7.1. アンサンブル学習
2.7.2. 半教師あり学習 (半教師付き学習)
2.8. モデルの適用範囲
2.8.1. データ範囲
2.8.2. データ中心からの距離
2.8.3. データ密度
2.8.4. アンサンブル学習
2.9. モデルの逆解析
2.9.1. グリッドサーチ
2.9.2. サンプリング
2.9.3. ベイズの定理
2.10. 実行するためのプログラム紹介
3. 分子設計・材料設計・プロセス設計・プロセス管理に関する最新の研究事例
3.1. 化学空間の可視化に基づく分子設計
3.2. 定量的構造物性 (活性) 相関モデルの逆解析に基づく分子設計
3.3. 定量的構造物性 (活性) 相関モデルの適用範囲を考慮した分子設計
3.4. 実験計画法による材料設計? 目標達成確率に基づく適応的実験計画法?
3.5. シミュレーションとインフォマティクス技術を活用したプロセス設計
4. まとめ・質疑応答
セミナー講師
金子 弘昌 氏
明治大学 理工学部 応用化学科 専任講師
【講師経歴】
2011年9月 東京大学大学院 工学系研究科 化学システム工学専攻 博士課程 修了
2009年4月~2011年9月 日本学術振興会特別研究員DC1
2011年10月~2011年12月 東京大学大学院 工学系研究科 化学システム工学専攻 特任助教
2012年1月~2017年3月 東京大学大学院 工学系研究科 化学システム工学専攻 助教
2017年4月~現在 明治大学 理工学部 応用化学科 専任講師
2018年12月~現在 国立研究開発法人 理化学研究所 客員主幹研究員(兼任)
2019年4月~現在 大阪大学 太陽エネルギー化学研究センター 招聘准教授(兼任)
2019年4月~現在 広島大学大学院 工学研究科 次世代自動車技術共同研究講座 客員准教授(兼任)
セミナー受講料
47,000円 + 税※ 資料付・昼食付
* メルマガ登録者は 42,000円 + 税
* アカデミック価格は 24,000円 + 税
★ アカデミック価格
学校教育法にて規定された国、地方公共団体、および学校法人格を
有する大学、大学院の教員、学生に限ります。申込みフォームに
所属大学・大学院を記入のうえ、備考欄に「アカデミック価格希望」と
記入してください。
★メルマガ会員特典
CMCリサーチメルマガ会員登録をされていない方で登録をご希望の方は、
申込みフォームの備考欄に「会員登録希望」とご記入ください。
セミナーのお申し込みと同時に会員登録をさせていただきますので、
今回の受講料より会員価格を適用いたします。
2名以上同時申込で申込者全員メルマガ会員登録をしていただいた場合、
2人目は無料(1名価格で2名まで参加可能)、3人目以降はメルマガ価格の半額です。
関連セミナー
もっと見る-

マテリアルズインフォマティクスのためのデータ解析
全国55,0002024-05-31

関連教材
もっと見る





関連記事
もっと見る-
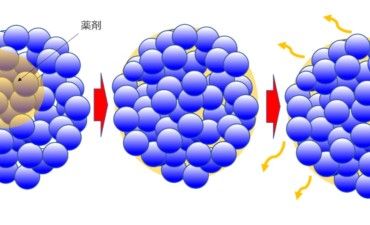
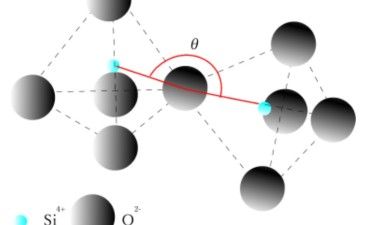
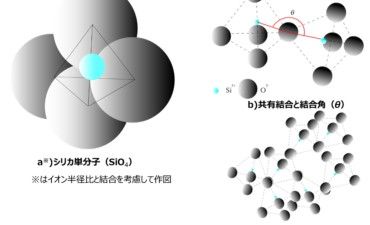
シリカと医薬品、医薬品添加剤に使用される合成シリカとは
【目次】 1. 合成シリカ 合成シリカの多くは、衣食住をはじめさまざまな産業で使用されていて直接お目にかかることはあまりありません... -

シリカと地熱発電、シリカスケールの発生を予防できる技術とは
【記事要約】 シリカと地熱発電、地熱発電は自然の環境に依存する要因が大きく、常に熱水の温度、圧力、シリカ濃度が変化している。これがシ...